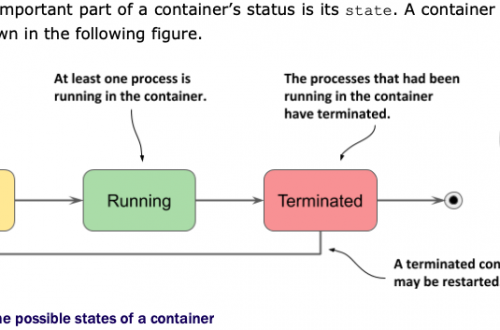
Kubernetes in Action读书笔记第二章:迈进Docker和Kubernetes的第一步
本章主要内容:
- 如何创建、运行、推送一个Docker image
- 配置kubectl命令行工具的命令补齐和对象名自动补齐
- 运行一个Kubernetes应用
- 对Kubernetes应用进行扩容缩容操作
Contents [hide]
1如何创建、运行、推送一个Docker image
1.1安装Docker并运行1个container
参考Docker官方文档来安装:https://docs.docker.com/engine/install/ 具体的安装步骤和流程就不再在这里赘述了。
接下来我们运行一个镜像名为busybox的container,这个image在Docker hub,即Docker的官方仓库上。
这个image里包含了标准的Unix命令行工具,如echo/ls、gzip等。我们在master节点上执行:
[root@master-node ~]# docker run busybox echo "Hello World...."Unable to find image 'busybox:latest' locallyTrying to pull repository docker.io/library/busybox ... latest: Pulling from docker.io/library/busybox009932687766: Pull complete Digest: sha256:afcc7f1ac1b49db317a7196c902e61c6c3c4607d63599ee1a82d702d249a0ccbStatus: Downloaded newer image for docker.io/busybox:latestHello World....[root@master-node ~]# 结合上面的命令执行输出,我们可以得到这条命令底层的执行流程图如下:
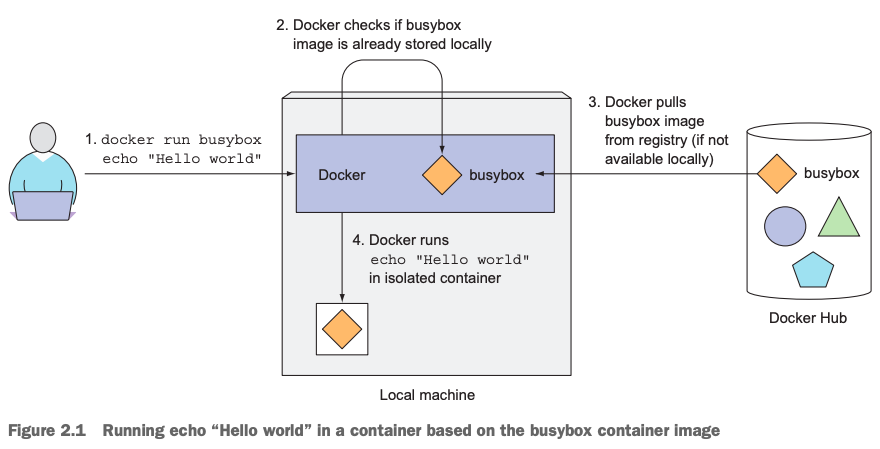
从本地机器搜索看看是否存在名为busybox的image?
不存在,则从Docker image registry查找并下载该image的最新版到本地机器,默认不带tag,则表示busybox:latest使用标签。
然后,Docker 通过该image启动并运行一个container,并且在该container中执行一条命令echo “Hello World…”,命令执行之后,便退出container,进而该container也退出运行状态。
1.1.1 如何运行其它image
docker run image_name|image_id1.1.2 如何运行不同版本的image
docker run image_name:tag1.2如何创建1个Docker image
1.2.1准备1个名为app.js的node.js文件
const http = require('http');const os = require('os');console.log("Kubia server starting...");var handler = function(request, response) { console.log("Received request from " + request.connection.remoteAddress); response.writeHead(200); response.end("You've hit " + os.hostname() + "\n");};var www = http.createServer(handler);www.listen(8080);通过node.js来启动运行一个web server,监听在8080端口,接收客户端发起的请求,返回一个200的状态码,并打印输出该web server所在主机名给客户端。
关于该部分代码,引入两个node.js的内置module,HTTP和OS,前者可以用来创建1个web server,OS可以用来操作读取主机信息。相关参考:https://www.w3schools.com/nodejs/nodejs_modules.asp
在本机Mac上演示如何运行和访问该应用,前提条件是执行app.js的机器必需安装了node.js的环境。当然,将来我们把这个app.js应用程序打成Docker image之后,就把node.js的环境打到该image文件里了。只要有可以运行Docker的环境就可以运行该image,而不再需要额外安装配置node.js。这也是本实验的一个演示目的。
session1,通过node app.js来启动该应用:
$ hostname MacBook-Air-3.local•asher at MacBook-Air-3 in ~/testdir$ pwd/Users/asher/testdir•asher at MacBook-Air-3 in ~/testdir$ lltotal 8drwxr-xr-x 3 asher staff 96 Feb 20 17:06 .drwxr-xr-x+ 144 asher staff 4608 Feb 20 17:06 ..-rw-r--r-- 1 asher staff 354 Feb 19 23:14 app.js•asher at MacBook-Air-3 in ~/testdir$ node -vv12.6.0•asher at MacBook-Air-3 in ~/testdir$ node app.js Kubia server starting...session2,模拟客户端发起请求:
$ curl localhost:8080You've hit MacBook-Air-3.local•asher at MacBook-Air-3 in ~/testdir$ curl 127.0.0.1:8080You've hit MacBook-Air-3.local•asher at MacBook-Air-3 in ~/testdir$ curl 192.168.3.3:8080You've hit MacBook-Air-3.local•asher at MacBook-Air-3 in ~/testdir$ 1.2.2准备Dockerfile
在和app.js的同级路径下,创建1个名为Dockerfile的文件,内容如下:
FROM node:7ADD app.js /app.jsENTRYPOINT ["node", "app.js"]第1行命令:我们需要使用名为node tag为7的基础镜像文件,作为我们生成image的基础;因为我们的程序是1个node.js的程序,我们需要1个可以执行node程序的环境。当然,我们也可以选择任意其它的基础镜像,只要它包含了可以运行node.js程序的环境即可。
第2行命令:表示我们要把当前路径下的app.js文件,添加到基础镜像node:7的根路径下,并且依然命名为app.js,即我们修改了这个基础镜像,在它的基础上添加了我们自己的文件;
第3行命令:表示一旦运行这个被我们修改过的image,或者是我们生成的这个最终的image时,就会在container中执行node app.js程序,这个不就是我们希望的结果吗?
这里的FROM、ADD、ENTRYPOINT是Dockerfile的关键字,先保持这样写。后面会再介绍说明。
1.2.3生成Docker image
有了我们自己的可执行程序app.js和Dockerfile之后,就可以构建生成1个Docker image了。
本地Docker环境:
$ docker -vDocker version 20.10.11, build dea9396•asher at MacBook-Air-3 in ~/testdir$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEdocker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBrenguzi/docker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBalpine/git latest c6b70534b534 3 months ago 27.4MB•asher at MacBook-Air-3 in ~/testdir$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES•asher at MacBook-Air-3 in ~/testdir$ 创建image:
$ docker build -t kubia .....=> => sha256:3245b5a1c52cbf0ae23d948fb94ef7b321e3dc54e1 131.86MB / 131.86MB 233.0s => => sha256:afa075743392fc2e79375c44e3ef285f775b722bbf27d01 4.38kB / 4.38kB 75.4s => => sha256:9fb9f21641cdf120516153e477e21bad887648cdced 119.15kB / 119.15kB 76.1s => => sha256:3f40ad2666bcec6baf03f4322c4736464de25d351740 15.68MB / 15.68MB 100.1s => => sha256:49c0ed396b49ee88dec473e3277b89a80d79a5eefeb 900.58kB / 900.58kB 95.9s => => extracting sha256:49c0ed396b49ee88dec473e3277b89a80d79a5eefebb96c0e1a64 0.1s => [2/2] ADD app.js /app.js 1.1s => exporting to image 0.1s => => exporting layers 0.1s => => writing image sha256:eea947f5757fde031b8ee276b3a2c646c14e63a40299c75d98 0.0s => => naming to docker.io/library/kubia 0.0s•asher at MacBook-Air-3 in ~/testdir$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEkubia latest eea947f5757f 33 minutes ago 660MBdocker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBrenguzi/docker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBalpine/git latest c6b70534b534 3 months ago 27.4MB•asher at MacBook-Air-3 in ~/testdir$ 成功之后,看到生成了我们需要的image文件kubia。上述命令解释:我们告诉Docker基于当前路径下的所有文件内容,生成1个名为kubia的image。这个当前路径是命令行上最后的那个”.”所表示的含义。-t表示完整的意思是打tag,这里kubia的kubia等价于kubia:latest,默认表示是最新版的tag。当然可以任意取一个其它我们想要的image名,不一定非要叫做kubia。
docker首先在指定的路径下(这里用点.来指定当前路径)找到Dockerfile,然后根据Dockerfile里的内容,再去构建我们需要的image。
下图是上面命令的执行流程:
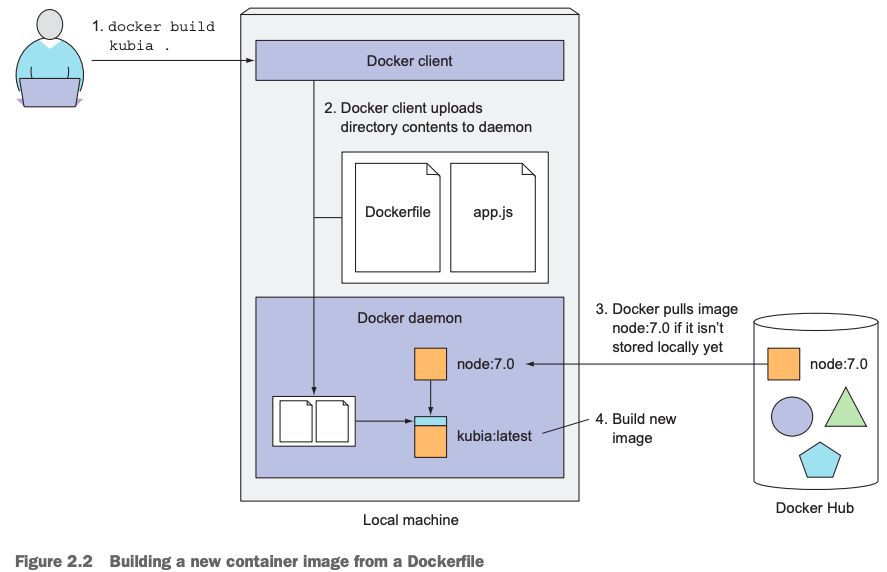
docker client(执行上述命令的工具)把需要用到的文件(这里就是当前路径下的Dockerfile和app.js文件)upload给docker daemon,由docker daemon根据Dockerfile里的执行,进行下载需要的基础镜像到本地(如果本地没有node:7 image的话),然后再构建我们需要的image文件。生成最终的image文件是由Docker daemon完成的,不是执行docker build -t xx_name yy_path命令的客户端完成的。
1.2.4再谈Docker image分层
在前面的第一章的3.3章节,我们提到docker image的分层除了可以实现image分发时的快速传递和多个container共享image layer之外,这里也顺便再次补充一点儿。我们在本地第1次执行docker build -t kubia .命令时,docker会默认在本地查找是否存在node:7的image,如果没有,则会从docker hub上下载该image到本地,这可能需要一些时间,但是,如果下次我们构建另外一个image,如果还需要用到该node:7作为基础镜像,则docker不会再次从docker hub上下载,因为本地已经存在。
另外,每一个docker image文件包含了若干layer,而不是仅仅只有1个layer。如,我们的Dockerfile中包含了3个命令,这里也需要注意的是,其实是docker从docker hub上下载了node:7基础镜像之后,当执行ADD app.js /app.js这条命令时,docker就在基础镜像上添加了1个layer,最后执行ENTRYPOINT [“node”,”app.js”]时,又添加了1个layer,只是这一层里添加的命令就是当通过该image来运行一个container时,会默认在container里运行这个命令:node app.js。
1.3如何运行我们创建的docker image
$ curl localhost:8080curl: (7) Failed to connect to localhost port 8080: Connection refused•asher at MacBook-Air-3 in ~/testdir$ docker psdocCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES•asher at MacBook-Air-3 in ~/testdir$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEkubia latest eea947f5757f 5 hours ago 660MBdocker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBrenguzi/docker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBalpine/git latest c6b70534b534 3 months ago 27.4MB•asher at MacBook-Air-3 in ~/testdir$ docker run --name kubia-container -p 8080:8080 -d kubia6fdb99edf0d69fe3a47b7f7ef889367d38f982b9c82e6aa277cabb29ac8725f1•asher at MacBook-Air-3 in ~/testdir$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES6fdb99edf0d6 kubia "node app.js" 2 minutes ago Up 2 minutes 0.0.0.0:8080->8080/tcp kubia-container•asher at MacBook-Air-3 in ~/testdir$ curl localhost:8080You've hit 6fdb99edf0d6•asher at MacBook-Air-3 in ~/testdir$ 我们通过docker run –name kubia-container -p 8080:8080 -d kubia这条命令,就把我们的app.js这个程序运行在container里了,并且通过curl localhost:8080命令访问了运行在这个container中的应用了。
其中:
docker run是关键字指令;
–name kubia-container,表示指定我们的container的名字;
-p 8080:8080表示指定我们本地机器(运行这个container的机器)上的8080端口映射到container里的8080端口,也就是意味着,当我们访问本机的8080端口时,其实就是相当于访问container的8080端口,而我们container里的8080端口上的服务是由我们的app.js程序提供的。
后面的-d 表示我们的container是以detach方式,即后台的方式运行的;
最后的kubia指定的是image名字,其实这里相当于是kubia:latest;如果需要其它版本或者说其它tag来区分的话,就必须得显示指定出来;
整个命令输出的字符串:6fdb99edf0d69fe3a47b7f7ef889367d38f982b9c82e6aa277cabb29ac8725f1表示的是这个container的id;
docker ps输出的结果中container id列印证了上述的输出,同时command列中的内容表示的在这个container中正在执行的命令,node app.js;
curl localhost:8080返回的结果中,不再是本机名,而是我们的container的主机名,也是container的id;
1.4查看container的详细信息
$ docker inspect kubia-container[ { "Id": "6fdb99edf0d69fe3a47b7f7ef889367d38f982b9c82e6aa277cabb29ac8725f1", "Created": "2022-02-20T14:19:03.006291201Z", "Path": "node", "Args": [ "app.js" ], "State": { "Status": "running", "Running": true, "Paused": false, "Restarting": false, "OOMKilled": false,......1.5进入container一探究竟
$ docker exec -it kubia-container bashroot@6fdb99edf0d6:/# hostname6fdb99edf0d6root@6fdb99edf0d6:/# ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 1.3 614440 26600 ? Ssl 14:19 0:00 node app.jsroot 13 0.2 0.1 20252 3276 pts/0 Ss 14:27 0:00 bashroot 22 0.0 0.1 17508 2132 pts/0 R+ 14:28 0:00 ps auxroot@6fdb99edf0d6:/#通过执行docker exec -it kubia-container bash命令,其中的
exec是关键字(execute),表示要进入container执行命令;
-it分别表示interactive,和tty,即已交互式的方式,开启一个pseudo terminal;
kubia-container,表示要进入哪个container;
bash,意味着进入container之后,执行1个bash;
强调:这里执行的ps aux输出结果中,看到1号进程node app.js和13号进程bash,它们其实就是进入container之后,被完全隔离的2个进程,同时它们的namespace完全一致。
root@6fdb99edf0d6:/# ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 1.3 614440 26600 ? Ssl 14:19 0:00 node app.jsroot 13 0.0 0.1 20252 3276 pts/0 Ss 14:27 0:00 bashroot 24 0.0 0.1 17508 2040 pts/0 R+ 14:42 0:00 ps auxroot@6fdb99edf0d6:/# ls -l /proc/1/ns/total 0lrwxrwxrwx 1 root root 0 Feb 20 14:42 cgroup -> cgroup:[4026532454]lrwxrwxrwx 1 root root 0 Feb 20 14:42 ipc -> ipc:[4026532375]lrwxrwxrwx 1 root root 0 Feb 20 14:42 mnt -> mnt:[4026532373]lrwxrwxrwx 1 root root 0 Feb 20 14:42 net -> net:[4026532378]lrwxrwxrwx 1 root root 0 Feb 20 14:42 pid -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 20 14:42 pid_for_children -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 20 14:42 time -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 20 14:42 time_for_children -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 20 14:42 user -> user:[4026531837]lrwxrwxrwx 1 root root 0 Feb 20 14:42 uts -> uts:[4026532374]root@6fdb99edf0d6:/# ls -l /proc/13/ns/total 0lrwxrwxrwx 1 root root 0 Feb 20 14:42 cgroup -> cgroup:[4026532454]lrwxrwxrwx 1 root root 0 Feb 20 14:42 ipc -> ipc:[4026532375]lrwxrwxrwx 1 root root 0 Feb 20 14:42 mnt -> mnt:[4026532373]lrwxrwxrwx 1 root root 0 Feb 20 14:42 net -> net:[4026532378]lrwxrwxrwx 1 root root 0 Feb 20 14:42 pid -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 20 14:42 pid_for_children -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 20 14:42 time -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 20 14:42 time_for_children -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 20 14:42 user -> user:[4026531837]lrwxrwxrwx 1 root root 0 Feb 20 14:42 uts -> uts:[4026532374]root@6fdb99edf0d6:/# 容器里运行的node app.js进程就被完全隔离了,此时它的pid=1,它认为它就是它所在那个容器的”全部”,此时它是看不到主机上任何其他进程的。但是,我们的主机上其实也运行着一个进程node app.js,只是主机上的该进程的pid完全不同于container中的pid。
如果我们的container是运行在Linux平台上的话,我们可以直接在Linux主机上执行ps aux|grep app.js来查看。如果我们的container是运行在Mac、Windows平台上的话,我们不能直接在主机上看到这个进程。需要进入到Docker给我们启动的一个VM里去,才能看的到。Docker另外运行了1个虚拟机,为什么这样呢?我们在前面提到,容器技术的本质是依赖于Linux的内核来实现的,Mac、Windows系统哪儿来的Linux内核呢。所以,Docker通过在这2个平台上启动一个VM来实现。
我这里的演示环境是Mac,所以,我可以通过下述命令,进入到我的Mac平台上的Docker的VM里:
docker run -it --rm --privileged --pid=host justincormack/nsenter1如下:
$ docker run -it --rm --privileged --pid=host justincormack/nsenter1Unable to find image 'justincormack/nsenter1:latest' locallylatest: Pulling from justincormack/nsenter15bc638ae6f98: Pull complete Digest: sha256:e876f694a4cb6ff9e6861197ea3680fe2e3c5ab773a1e37ca1f13171f7f5798eStatus: Downloaded newer image for justincormack/nsenter1:latest•/ # ps aux|grep app.js 2830 root 0:00 node app.js 2998 root 0:00 grep app.js/ # ps aux|grep bash 2879 root 0:00 bash 3083 root 0:00 grep bash/ # ls -l /proc/2830/ns/total 0lrwxrwxrwx 1 root root 0 Feb 21 01:47 cgroup -> cgroup:[4026532454]lrwxrwxrwx 1 root root 0 Feb 21 01:47 ipc -> ipc:[4026532375]lrwxrwxrwx 1 root root 0 Feb 21 01:47 mnt -> mnt:[4026532373]lrwxrwxrwx 1 root root 0 Feb 21 01:47 net -> net:[4026532378]lrwxrwxrwx 1 root root 0 Feb 21 01:47 pid -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 21 01:47 pid_for_children -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 21 01:47 time -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 21 01:47 time_for_children -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 21 01:47 user -> user:[4026531837]lrwxrwxrwx 1 root root 0 Feb 21 01:47 uts -> uts:[4026532374]/ # ls -l /proc/2879/ns/total 0lrwxrwxrwx 1 root root 0 Feb 21 01:47 cgroup -> cgroup:[4026532454]lrwxrwxrwx 1 root root 0 Feb 21 01:47 ipc -> ipc:[4026532375]lrwxrwxrwx 1 root root 0 Feb 21 01:47 mnt -> mnt:[4026532373]lrwxrwxrwx 1 root root 0 Feb 21 01:47 net -> net:[4026532378]lrwxrwxrwx 1 root root 0 Feb 21 01:47 pid -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 21 01:47 pid_for_children -> pid:[4026532376]lrwxrwxrwx 1 root root 0 Feb 21 01:47 time -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 21 01:47 time_for_children -> time:[4026531834]lrwxrwxrwx 1 root root 0 Feb 21 01:47 user -> user:[4026531837]lrwxrwxrwx 1 root root 0 Feb 21 01:47 uts -> uts:[4026532374]/ # •通过docker run -it –rm –privileged –pid=host justincormack/nsenter1进入到Mac平台上的Docker VM之后,我们可以看到执行的node app.js进程号为2830,且前面我们执行的另外一个命令的bash进程号为2879。且这2个进程由于所在的container相同,所以他们的namespace也完全相同。
Mac上进入Docker VM的命令,docker run -it –rm –privileged –pid=host justincormack/nsenter1可以参考:https://gist.github.com/BretFisher/5e1a0c7bcca4c735e716abf62afad389
然后,也可以看到运行在container中的进程它的文件系统也是独立的,如上的node app.js它能看到的文件系统就是它所在的container中的文件系统:
root@6fdb99edf0d6:/# lsapp.js bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr varroot@6fdb99edf0d6:/# node -vv7.10.1root@6fdb99edf0d6:/# which node/usr/local/bin/noderoot@6fdb99edf0d6:/# ps -ef|grep noderoot 1 0 0 Feb20 ? 00:00:00 node app.jsroot@6fdb99edf0d6:/# 看到里面的除了我们引用的那个基础的node:7镜像的文件系统,同时还包含了我们手工添加进去的app.js文件。也看到我们之所以可以在container中执行node app.js,是因为container中有了我们需要的执行node.js的node环境。
1.6删除和停止container
$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES6fdb99edf0d6 kubia "node app.js" 12 hours ago Up 12 hours 0.0.0.0:8080->8080/tcp kubia-container•asher at MacBook-Air-3 in ~/testdir$ docker stop kubia-containerkubia-container•asher at MacBook-Air-3 in ~/testdir$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES•asher at MacBook-Air-3 in ~/testdir$ docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES6fdb99edf0d6 kubia "node app.js" 12 hours ago Exited (137) 5 seconds ago kubia-container•asher at MacBook-Air-3 in ~/testdir$ docker rm kubia-containerkubia-container•asher at MacBook-Air-3 in ~/testdir$ docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES•asher at MacBook-Air-3 in ~/testdir$ 1.7推送image到Docker hub
Docker hub的地址为:https://hub.docker.com/ 在推送之前,我们需要注册一个用户,然后把我们的image打成Docker hub需要的固定格式:docker_hub_username/image_name:tag ,你的用户名/镜像名:tag版本
我们通过docker tag命令来把我们本地的名为kubia的image打成我们需要的格式:renguzi/kubia:mytag 其中的renguzi是我的Docker hub注册用户名,kubia是image名,mytag是我打的标签。
docker tag source_image target_image;这是该命令的使用方式。
$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEkubia latest eea947f5757f 17 hours ago 660MBdocker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBrenguzi/docker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBalpine/git latest c6b70534b534 3 months ago 27.4MBjustincormack/nsenter1 latest c81481184b1b 4 years ago 101kB•asher at MacBook-Air-3 in ~/testdir$ docker tag kubia renguzi/kubia:mytag•asher at MacBook-Air-3 in ~/testdir$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEkubia latest eea947f5757f 17 hours ago 660MBrenguzi/kubia mytag eea947f5757f 17 hours ago 660MBdocker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBrenguzi/docker101tutorial latest f7c3e1736982 5 weeks ago 28.8MBalpine/git latest c6b70534b534 3 months ago 27.4MBjustincormack/nsenter1 latest c81481184b1b 4 years ago 101kB•asher at MacBook-Air-3 in ~/testdir$ 推送到远端Docker hub:
$ docker push renguzi/kubia:mytagThe push refers to repository [docker.io/renguzi/kubia]856cd6a90642: Pushed ab90d83fa34a: Mounted from library/node 8ee318e54723: Mounted from library/node e6695624484e: Mounted from library/node da59b99bbd3b: Mounted from library/node 5616a6292c16: Mounted from library/node f3ed6cb59ab0: Mounted from library/node 654f45ecb7e3: Mounted from library/node 2c40c66f7667: Mounted from library/node mytag: digest: sha256:ddcb06c69b83188d3981d96fbf2291083ac6e1b2f58627b809ecc47790547392 size: 2213•asher at MacBook-Air-3 in ~/testdir$ •经过一段时间之后,可以看到推送成功。首次推送的时候,可能需要通过docker login来登录到远程仓库。
[root@node-1 ~]# docker loginLogin with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.Username: renguziPassword: Login Succeeded[root@node-1 ~]# 1.8在其它机器运行该image
如下在一台可以运行docker容器,但是不能执行node.js程序的Linux机器上,我们可以直接通过docker来运行前面我们提交到docker hub中的renguzi/kubia:mytag这个image:
[root@node-1 ~]# docker -vDocker version 1.13.1, build 7d71120/1.13.1[root@node-1 ~]# node -v-bash: node: 未找到命令[root@node-1 ~]# docker run --name kubia -p 8080:8080 -d renguzi/kubia:mytagUnable to find image 'renguzi/kubia:mytag' locallyTrying to pull repository docker.io/renguzi/kubia ... mytag: Pulling from docker.io/renguzi/kubiaad74af05f5a2: Pull complete 2b032b8bbe8b: Extracting [================> ] 6.488 MB/19.26 MBa9a5b35f6ead: Download complete 3245b5a1c52c: Downloading [==================================> ] 92.11 MB/131.9 MBafa075743392: Download complete ...07a0b0fe04da: Pull complete Digest: sha256:ddcb06c69b83188d3981d96fbf2291083ac6e1b2f58627b809ecc47790547392Status: Downloaded newer image for docker.io/renguzi/kubia:mytagf85f999adad2cd539ae24ff35a7ded2e4679d613048ed6483d7f054694345409[root@node-1 ~]# curl localhost:8080You've hit 7f7c85689179[root@node-1 ~]# curl 172.16.11.148:8080You've hit 7f7c85689179[root@node-1 ~]# 终于告一段落,我们原本需要自己安装配置node.js环境才可以执行我们的app.js,现在我们通过把该程序打成docker image,然后可以使之运行在docker container中,到最后我们把这个image push到docker hub。进而使得任意一台机器,只要它可以运行docker,可以访问docker hub,就可以pull该image到本地,并最终通过运行该image,进而启动一个隔离的container环境。
2 配置kubectl命令行工具的命令补齐和对象名自动补齐
我们在前面的搭建Kubernetes集群环境章节里,已经安装部署了3个节点的Kubernetes cluster。我们可以通过登录到master节点查看集群状态:
[root@master-node ~]# kubectl cluster-infoKubernetes control plane is running at https://172.16.11.168:6443CoreDNS is running at https://172.16.11.168:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy•To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.[root@master-node ~]# 这里,根据作者在书中提到,我们可以通过在主机上安装bash-completion软件包来实现kubectl命令补齐和对象名自动补全,其功能类似于bash shell的tab补全和命令补齐。
[root@master-node ~]# yum install bash-completion...Running transaction 正在安装 : 1:bash-completion-2.1-8.el7.noarch 1/1 验证中 : 1:bash-completion-2.1-8.el7.noarch 1/1 •已安装: bash-completion.noarch 1:2.1-8.el7 •完毕![root@master-node ~]# 然后,在root的~/.bash_profile里添加:
source <(kubectl completion bash)自此,当我们在命令上上执行kubectl 命令,以及查看和处理Kubernetes的各种对象,比如pod,service等,我们就可以通过tab键来自动补全我们的命令,或者对象名。这就是模拟了bash shell的命令自动补齐和文件名补全的功能。
3 运行一个Kubernetes应用
前面我们的应用是跑在docker容器里的,接下来我们想要把应用运行在Kubernetes中去。常规的操作是我们需要准备一份程序清单(1个yaml或者json格式的文件)给到Kubernetes的API server,但是,鉴于我们是第一次运行Kubernetes的应用,所以我们直接通过命令来操作,待逐渐熟悉Kubernetes之后,我们再采用传统的方式在Kubernetes上部署应用。
3.1在Kubernetes上运行1个ReplicationController
作者在原书P74使用的命令,在他当时使用的低版本的Kubernetes上可以正常使用。但是,在我这边的Kubernetes v1.23上,已经不能用了:
[root@master-node ~]# kubectl run kubia --image=luksa/kubia --port=8080 --generator=run/v1Error: unknown flag: --generatorSee 'kubectl run --help' for usage.[root@master-node ~]# 参考链接:https://community.kodekloud.com/t/unknown-tag-generator/25444
于是,我们还是采用最正宗的yaml方式来部署一个ReplicationController(这里没有一上来就部署Deployment资源,是有原因的,Deployment更高级别的抽象对象,而ReplicationController则比较偏底层,我们先从底层了解开始):kubia-rc.yaml源于源码第4章路径下(kubernetes-in-action/Chapter04/kubia-rc.yaml ),把replicas从3改为1了。
[root@master-node ~]# kubectl apply -f kubia-rc.yaml replicationcontroller/kubia created[root@master-node ~]# 通过下述命令来查看部署的ReplicationController和pods(加上-owide,表示显示对象的更多信息):
[root@master-node ~]# kubectl get rc -owideNAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTORkubia 1 1 1 33s kubia luksa/kubia app=kubia[root@master-node ~]# kubectl get pods -owideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESkubia-lzmxz 1/1 Running 0 43s 10.244.2.25 node-2 <none> <none>[root@master-node ~]# 也许我们刚从Docker的世界里赶过来,想要看看我们刚刚通过Kubernetes创建和运行的是哪个container?但是,不要,我们要记住,在Kubernetes的世界里,我们管理和维护的基本单元是一个被称作Pod的玩意儿。我们可以这么简单理解,pod就是对container的封装,一个pod可以包含1个或者多个container。pod可以被理解为一个逻辑的机器,该机器可以有自己的独立IP地址,主机名。运行在同一个pod里的container拥有相同的namespace,运行在不同pod里的container的namespace不同,即使这些不同的pod运行在同一个worker node上。
顺便补充一句:在Kubernetes的世界里,其实我们不应该也不需要直接去管理和维护pod,而应该管理和维护的是在pod之上抽象出来的对象,如:service,Deployment,ReplicaSet等。随着学习的深入,我们才能理解这句话的意思。先学着吧,边学边看边理解边吸收。
A pod is a group of one or more tightly related containers that will always run together on the same worker node and in the same Linux namespace(s). Each pod is like a separate logical machine with its own IP, hostname, processes, and so on, running a single application. The application can be a single process, running in a single container, or it can be a main application process and additional supporting processes, each running in its own container. All the containers in a pod will appear to be running on the same logical machine, whereas containers in other pods, even if they’re running on the same worker node, will appear to be running on a different one.
P75
我们再来回过头看一下上面的kubectl get rc -owide命令的输出结果:我们创建了1个名为kubia的ReplicationController,我们DESIRED希望的|要求的个数是1个,当前CURRENT正好有1个,而且READY的也是1个,一切刚刚好。AGE字段描述的是这个ReplicationController截止到当前已经生存了33秒,Container指的是它底层的容器的名字;IMAGES是它的container所依赖的image名字,SELECTOR是它的选择器,这个我们先了解,后面会再详细涉及到。
kubectl get pods -owide的结果中的字段:STATUS 指的pod的当前状态,RESTARTS,pod重启的次数,我们知道Kubernetes会自动帮我们维护和管理pod,在某些场景下会reschedule到其它node,IP是当前pod的IP地址10.244.2.25,需要注意的是,pod的IP是有可能发生变化的,NODE表示当前pod运行在Kubernetes cluster中的哪个节点上,这里是运行在node-2上。这里,我们可以到node-2上去验证:
[root@node-2 ~]# hostnamenode-2[root@node-2 ~]# docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES58ef90f9f8a6 docker.io/luksa/kubia@sha256:3f28e304dc0f63dc30f273a4202096f0fa0d08510bd2ee7e1032ce600616de24 "node app.js" 18 minutes ago Up 18 minutes k8s_kubia_kubia-lzmxz_default_74d86042-d3a5-49af-aedf-a84ee14fed4d_066a05ca29855 registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 18 minutes ago Up 18 minutes k8s_POD_kubia-lzmxz_default_74d86042-d3a5-49af-aedf-a84ee14fed4d_0...省略其它运行的container信息[root@node-2 ~]# docker exec -it 58ef90f9f8a6 /bin/bashroot@kubia-lzmxz:/# hostnamekubia-lzmxzroot@kubia-lzmxz:/# ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 0.2 616240 17604 ? Ssl 03:20 0:00 node app.jsroot 20 0.0 0.0 20236 2044 ? Ss 06:33 0:00 /bin/bashroot 29 0.0 0.0 17488 1132 ? R+ 06:34 0:00 ps auxroot@kubia-lzmxz:/# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever3: eth0@if46: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default link/ether da:fe:fd:8f:86:03 brd ff:ff:ff:ff:ff:ff inet 10.244.2.25/24 brd 10.244.2.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::d8fe:fdff:fe8f:8603/64 scope link tentative dadfailed valid_lft forever preferred_lft foreverroot@kubia-lzmxz:/# 找到container id,然后通过docker exec -it 58ef90f9f8a6 /bin/bash 进入container内部,执行hostname,ps aux,ip a分别查看container的主机名,以及它内部所运行的进程信息,和network interface信息。看到的主机名为kubia-lzmxz,以及IP:10.244.2.24和我们从container外部看到的信息一样。
接下来,我们可以访问我们的pod:
[root@master-node ~]# kubectl get pods -owideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESkubia-lzmxz 1/1 Running 0 3h6m 10.244.2.25 node-2 <none> <none>[root@master-node ~]# curl 10.244.2.25:8080You've hit kubia-lzmxz[root@master-node ~]# 接下来,再让我们把目光转向那个yaml文件,kubia-rc.yaml:
[root@master-node ~]# cat kubia-rc.yaml apiVersion: v1kind: ReplicationControllermetadata: name: kubiaspec: replicas: 1 selector: app: kubia template: metadata: labels: app: kubia spec: containers: - name: kubia image: luksa/kubia ports: - containerPort: 8080一个完整的yaml文件,通常第一行都是版本号:通常为v1,然后就是对象的资源类型。接下来包含3个部分:
- 元数据:对象名,所在namespace,资源类型,标签信息等;
- 描述信息:该类型的对象具体包含的内容,container,volume等信息;
- 状态信息:当前对象的状态信息。
关于yaml:Yet Another Markup Language,也叫做YAML Arenot Markup Language。它是JSON的superset,任何一份合法的json文件都可以转为yaml。我们在Kubernetes里,建议选用yaml格式的文件来作为我们的manifest,毕竟相比于json,它的可阅读性更好一些。随着,我们对于Kubernetes中不同类型对象的yaml文件的使用和编辑,我们会慢慢的习惯于这种格式的声明文件。当然,我也会抽出时间和精力来另外写一些关于yaml的教程内容分享出来。
ReplicationController解释:它是封装在pod之上的用于统一管理调度pod的Kubernetes对象,我们创建ReplicationController对象,ReplicationController帮我们创建pod,我们不直接创建和管理pod。ReplicationController和pod通过label selector关联在一起。如果由ReplicationController创建的pod出现意外故障而宕掉,ReplicationController会自动帮我们重新拉起1个新的pod,用于取代那个故障的pod。而如果pod是我们手工创建的,它出现故障的话,Kubernetes不会干预和管理这个故障的pod。通过ReplicationController可以轻松容易的对它所管理的pod进行扩容缩容操作。ReplicationController对象渐渐的被ReplicaSet取代。关于它的进一步深入学习将在第4章。
3.2Kubernetes上运行ReplicationController的流程
好了,再一次让我们总览一下,在Kubernetes上部署一个应用的总体流程:
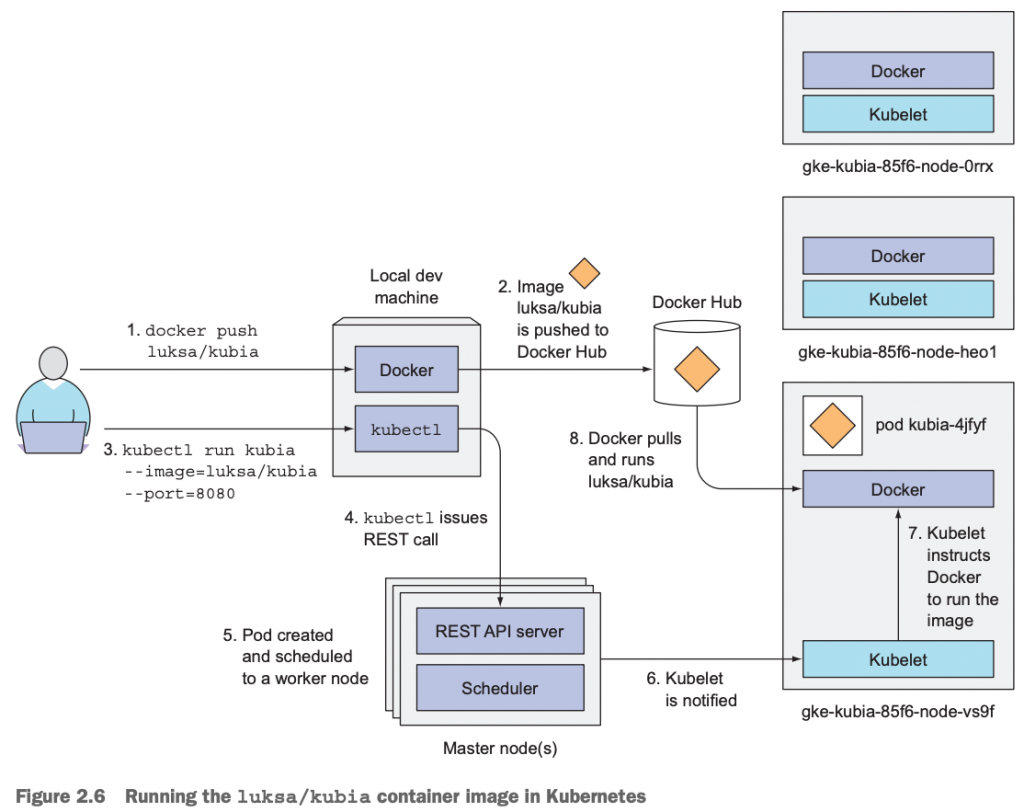
上图描述了,一个3节点的Kubernetes环境,部署一个应用的流程图,大概有8个步骤。
3.3通过service把ReplicationController暴露出去
在我们深入了解学习pod之前,我们先记住,我们的应用是跑在pod里的container里的,我们应该怎么访问这些应用呢?我们可以通过pod的IP访问,如上例:我们可以通过curl 10.244.2.25:8080进行服务的访问。但是,但是我们不应该也不需要通过pod的IP去访问服务。而是应该通过service去访问,这里的service是Kubernetes里的基于pod之上抽象出来的一种对象。后面的第五章,我们会详细深入学习。
这里,由于我们的Kubernetes cluster环境是部署在本地,无法提供基于loadbalancer类型(该类型服务通常由云服务厂商提供支持,具体后面第5章讲解)的service。当然,如果创建服务时指定了服务类型为LoadBalancer,如果我们的Kubernetes cluster不支持LoadBalancer的话,则会自动将该服务降级为NodePort类型的服务。这里就是这种情形,服务自动变为NodePort类型的service。关于Service的类型,我们先了解即可。
[root@master-node ~]# kubectl expose replicationcontroller kubia --type=LoadBalancer --name kubia-httpservice/kubia-http-external-name exposed[root@master-node ~]# [root@master-node ~]# kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45hkubia-http LoadBalancer 10.105.153.40 <pending> 8080:30928/TCP 20m[root@master-node ~]# kubectl get svc -owideNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTORkubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45h <none>kubia-http LoadBalancer 10.105.153.40 <pending> 8080:30928/TCP 21m app=kubia[root@master-node ~]#这里,我们创建了1个类型为NodePort(其实是由Loadbalancer降级来的)的service,它的名字是kubia-http,它是封装在名为kubia的ReplicationController之上的对象。从输出结果中的30928我们可以知道,这时候,我们可以通过这个Kubernetes集群的任意节点+这个端口号就可以访问我们的服务了。如下,我在我的Mac上,执行:
MacBook-Air-3:~ root# curl 172.16.11.148:30928You've hit kubia-lzmxzMacBook-Air-3:~ root# curl 172.16.11.161:30928You've hit kubia-lzmxzMacBook-Air-3:~ root# curl 172.16.11.168:30928You've hit kubia-lzmxzMacBook-Air-3:~ root# 这也就意味着,我们的应用程序,跑在pod里的container里的那个node.js的app.js程序提供的服务,可以通过我们的3个节点进行访问了。而我们不需要关注这个container是跑在哪个pod上,这个pod的IP是什么,这个pod是运行在哪个node上。由于pod可能会从一个node调度到另外一个新的node上,且pod的IP地址会发生变化,我们不能保证通过一个固定的IP去访问服务。这就是为什么Kubernetes要在pod之上再封装1层service对象的根本原因了。
补充:作者在原书中使用的service类型是Loadbalancer,而这需要1个公网IP,如果你的Kubernetes运行在云服务商,如Google Kubernetes Engine或者AWS以及其他厂商的话,可以完成该类型service的创建。
Kubernetes的service类型,通常有4类:ClusterIP,NodePort,LoadBalancer,ExternalName。具体的内容,我们谈到service章节时,再深入学习了解。
3.4小结pod、container、ReplicationController、service的关系
我们的应用程序是运行在container中的,container跑在pod里,pod被ReplicationController管控,用户通过service来访问我们的服务。当service对象收到client请求时,它把请求转发到在它之下的ReplicationController管控的任意1个pod上,最后到达运行在pod的container里的应用上了。
这里更精髓的描述,可以翻看原书pdf的P80页(页面数是48)。作者描述的是真精髓。
4扩缩容Kubernetes应用
4.1扩容Kubernetes应用
前面,我们了解到在Kubernetes里我们不应该直接去创建和管理pod,而应该通过创建它上层的对象(ReplicationController,replicaSet、Deployment),然后通过上层的对象去管理和维护pod。也知道了,由ReplicationController管理的pod可以轻松快速进行扩缩容操作。
[root@master-node ~]# kubectl get rcNAME DESIRED CURRENT READY AGEkubia 1 1 1 5h18m[root@master-node ~]# kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 10.96.0.1 <none> 443/TCP 46hkubia-http NodePort 10.105.153.40 <none> 8080:30928/TCP 105m[root@master-node ~]# kubectl get podsNAME READY STATUS RESTARTS AGEkubia-lzmxz 1/1 Running 0 5h18m[root@master-node ~]# kubectl scale replicationcontroller kubia --replicas=3replicationcontroller/kubia scaled[root@master-node ~]# kubectl get podsNAME READY STATUS RESTARTS AGEkubia-lzmxz 1/1 Running 0 5h19mkubia-tm6dn 0/1 ContainerCreating 0 3skubia-vrbt6 0/1 ContainerCreating 0 3s[root@master-node ~]# 我们通过命令kubectl scale replicationcontroller kubia –replicas=3对名为kubia的ReplicationController进行扩容,要求它帮我们创建3个pod出来,–replicas=3实现的。
过一会儿之后,我们再次查看,发现多2个pod,且replicationcontrollers 的状态发生变化:
[root@master-node ~]# kubectl get replicationcontrollers NAME DESIRED CURRENT READY AGEkubia 3 3 3 5h25m[root@master-node ~]# kubectl get podsNAME READY STATUS RESTARTS AGEkubia-lzmxz 1/1 Running 0 5h25mkubia-tm6dn 1/1 Running 0 6m25skubia-vrbt6 1/1 Running 0 6m25s[root@master-node ~]# 前面,我们不是讲到了通过service访问应用,而不应该通过pod访问的好处吗?也提到,当我们的请求到达service时,service把请求转发到由它管理的底层的任意一个pod上。我们现在知道,当前的service对象kubia-http通过NodePort类型的服务暴露出去,我们再次访问它验证一下:
MacBook-Air-3:~ root# curl 172.16.11.168:30928You've hit kubia-lzmxzMacBook-Air-3:~ root# curl 172.16.11.168:30928You've hit kubia-vrbt6MacBook-Air-3:~ root# curl 172.16.11.168:30928You've hit kubia-vrbt6MacBook-Air-3:~ root# curl 172.16.11.168:30928You've hit kubia-vrbt6MacBook-Air-3:~ root# curl 172.16.11.168:30928You've hit kubia-tm6dnMacBook-Air-3:~ root# 从返回的结果,我们可以看到,服务请求确实到了底层的不同的pod上了。
4.2 缩容Kubernetes应用
接下来,演示一下如何缩容Kubernetes应用。我们再次把这里的kubia这个ReplicationController管理的pod的副本数从3个改为最开始的1个。
修改之前,我们通过kubectl get replicationcontrollers kubia查看其状态:
[root@master-node ~]# kubectl get replicationcontrollers NAME DESIRED CURRENT READY AGEkubia 3 3 3 5h32m[root@master-node ~]# kubectl get replicationcontrollers kubiaNAME DESIRED CURRENT READY AGEkubia 3 3 3 5h32m[root@master-node ~]# kubectl get replicationcontrollers kubia -oyamlapiVersion: v1kind: ReplicationControllermetadata: annotations:...spec: replicas: 3 selector: app: kubia...status: availableReplicas: 3 fullyLabeledReplicas: 3 observedGeneration: 2 readyReplicas: 3 replicas: 3[root@master-node ~]# kubectl get replicationcontrollers kubia -oyaml以输出yaml格式到终端上,我们看到其副本数是3个。
通过kubectl edit replicationcontrollers kubia 对其进行修改:
[root@master-node ~]# kubectl edit replicationcontrollers kubia # Please edit the object below. Lines beginning with a '#' will be ignored,# and an empty file will abort the edit. If an error occurs while saving this file will be# reopened with the relevant failures.#apiVersion: v1kind: ReplicationController...spec: replicas: 3 #将这里的3改为1,保存退出即可修改之后:
[root@master-node ~]# kubectl get replicationcontrollers NAME DESIRED CURRENT READY AGEkubia 1 1 1 5h37m[root@master-node ~]# kubectl get podsNAME READY STATUS RESTARTS AGEkubia-lzmxz 1/1 Running 0 5h37mkubia-tm6dn 1/1 Terminating 0 18mkubia-vrbt6 1/1 Terminating 0 18m[root@master-node ~]# 过一会儿之后,我们会发现ReplicationController和pod的状态都发生了变化,pod从3个变成了1个,其中有2个状态为Terminating。
5 本章小结
学完本章,我们掌握了:
- 如何创建、运行一个Docker container;
- 如何把我们的应用打成Docker image,以及底层原理流程;
- 如何把我们的Docker image push到Docker hub;
- 在Kubernetes上运行我们自己的Docker image及底层原理流程;
- 设置了kubectl命令行工具的命令补齐和对象名补全;
- 了解了pod、container、ReplicationController、service的关系;
- 快速水平扩、缩容我们的Kubernetes应用;