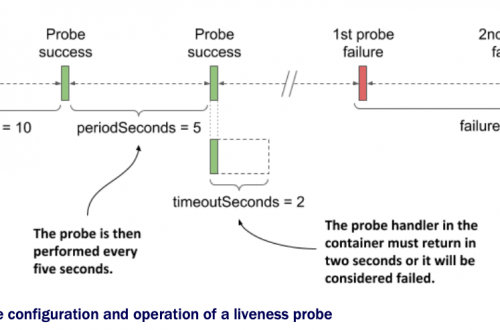
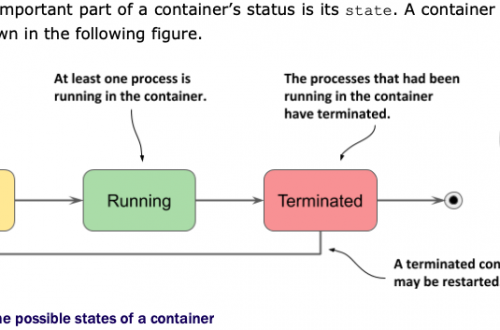
如何在CentOS 7上一步一步安装Kubernetes cluster v1.23
Contents
- 一环境说明
- 二 配置步骤
- 0 2个机器分别修改hostname
- 1 2个机器分别修改/etc/hosts:
- 2 2个机器分别关闭SELINUX
- 3 2个机器分别关闭防火墙
- 4 2个机器分别关闭SWAP
- 5 reboot 2个机器
- 6 2个机器分别添加kubernetes Repo
- 7 2个机器分别安装指定版本v1.23.1的kubeadm和docker
- 8 2个机器分别启动kubelet和docker服务
- 9 关于指定docker虚拟网卡地址的情况
- 10 关于启动kubelet服务报错的情况说明
- 11 Initialize Kubernetes Master and Setup Default User
- 12 配置pod network
- 13 添加worker节点
- 14 master安装配置bash-completion
- 三 测试验证cluster
- 四 小结和链接
一环境说明
配置1个master node,1个worker node的kubernetes cluster,其中版本指定为v1.23.1:
| IP address | role | hostname | Memory | kernel version | OS version |
|---|---|---|---|---|---|
| 172.17.1.21 | master node | master21 | 4G | 3.10.0-1160.66.1.el7.x86_64 x86_64 | CentOS Linux release 7.9.2009 (Core) |
| 172.17.1.22 | worker node | worker22 | 64G | 3.10.0-1160.el7.x86_64 x86_64 | CentOS Linux release 7.9.2009 (Core) |
二 配置步骤
0 2个机器分别修改hostname
#master [root@localhost ~]# hostnamectl set-hostname master21 [root@localhost ~]# hostname master21 [root@localhost ~]# #worker [root@localhost ~]# hostnamectl set-hostname worker22 [root@localhost ~]# hostname worker22 [root@localhost ~]# #退出当前会话,重新登录,shell命令行获取新hostname
1 2个机器分别修改/etc/hosts:
# master,执行下述脚本 cat <<EOF>>/etc/hosts 172.17.1.21 master21 172.17.1.22 worker22 EOF [root@master21 ~]# ping worker22 PING worker22 (172.17.1.22) 56(84) bytes of data. 64 bytes from worker22 (172.17.1.22): icmp_seq=1 ttl=64 time=0.377 ms 64 bytes from worker22 (172.17.1.22): icmp_seq=2 ttl=64 time=0.410 ms ^C --- worker22 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1000ms rtt min/avg/max/mdev = 0.377/0.393/0.410/0.025 ms [root@master21 ~]# # worker,执行下述脚本 [root@worker22 ~]# cat <<EOF>>/etc/hosts > 172.17.1.21 master21 > 172.17.1.22 worker22 > EOF [root@worker22 ~]# ping master21 PING master21 (172.17.1.21) 56(84) bytes of data. 64 bytes from master21 (172.17.1.21): icmp_seq=1 ttl=64 time=0.376 ms 64 bytes from master21 (172.17.1.21): icmp_seq=2 ttl=64 time=0.300 ms ^C --- master21 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1000ms rtt min/avg/max/mdev = 0.300/0.338/0.376/0.038 ms [root@worker22 ~]#
2 2个机器分别关闭SELINUX
sed -i 表示原地修改文件,–follow-symlinks表示连带软连接文件一起修改,’s/xxx/yy/g’,通过正在,表示匹配到xx,则就将其修改为yy。
[root@localhost ~]# setenforce 0 [root@localhost ~]# sed -i --follow-symlinks 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux [root@localhost ~]#
3 2个机器分别关闭防火墙
[root@localhost ~]# systemctl stop firewalld [root@localhost ~]# systemctl disable firewalld
具体是实际情况而定,可能需要开启Firewalls,同时开放对应的端口。
4 2个机器分别关闭SWAP
#mater
[root@master21 ~]# free -m
total used free shared buff/cache available
Mem: 3789 160 3302 8 326 3399
Swap: 8127 0 8127
[root@master21 ~]# swapoff -a
[root@master21 ~]# free -m
total used free shared buff/cache available
Mem: 3789 154 3308 8 326 3405
Swap: 0 0 0
[root@master21 ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Mon Jun 13 15:57:27 2022
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=ea789fa2-8801-4022-849a-4b6dd779e4c8 /boot xfs defaults 0 0
/dev/mapper/centos-data /data xfs defaults 0 0
# config kubernetes,disabled the SWAP
#/dev/mapper/centos-swap swap swap defaults 0 0
[root@master21 ~]#
#worker 重复上述步骤
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 64265 1915 61992 8 357 61883
Swap: 31455 0 31455
[root@localhost ~]# swapoff -a
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 64265 1891 62016 8 357 61907
Swap: 0 0 0
[root@localhost ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Mon Jun 13 16:31:10 2022
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=168bd924-550f-4083-a51a-cef81d4868c8 /boot xfs defaults 0 0
/dev/mapper/centos-data /data xfs defaults 0 0
#config kubernetes,disabled the SWAP
#/dev/mapper/centos-swap swap swap defaults 0 0
[root@localhost ~]# 5 reboot 2个机器
#master
[root@master21 ~]# reboot
...
Last login: Tue Jun 14 10:34:45 2022 from 172.16.135.110
[root@master21 ~]# free -m
total used free shared buff/cache available
Mem: 3789 158 3499 8 130 3439
Swap: 0 0 0
[root@master21 ~]#
#worker 重复上述步骤
[root@worker22 ~]# reboot
...
Last login: Tue Jun 14 10:40:10 2022 from 172.16.135.110
[root@worker22 ~]# free -m
total used free shared buff/cache available
Mem: 64265 1896 62185 8 183 61914
Swap: 0 0 0
[root@worker22 ~]# 6 2个机器分别添加kubernetes Repo
由于国内网络原因,使用阿里云镜像地址:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
7 2个机器分别安装指定版本v1.23.1的kubeadm和docker
#master
[root@master21 ~]# yum install kubeadm-1.23.1 kubelet-1.23.1 kubectl-1.23.1 docker
已加载插件:fastestmirror
...
#如果有类似下述错误:
[root@master21 ~]# yum install kubeadm-1.23.1 kubelet-1.23.1 kubectl-1.23.1 docker
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
kubernetes/signature | 844 B 00:00:00
从 https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg 检索密钥
导入 GPG key 0x13EDEF05:
用户ID : "Rapture Automatic Signing Key (cloud-rapture-signing-key-2022-03-07-08_01_01.pub)"
指纹 : a362 b822 f6de dc65 2817 ea46 b53d c80d 13ed ef05
来自 : https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
是否继续?[y/N]:y
从 https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg 检索密钥
kubernetes/signature | 1.4 kB 00:00:18 !!!
https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/repodata/repomd.xml: [Errno -1] repomd.xml signature could not be verified for kubernetes
正在尝试其它镜像。
....
failure: repodata/repomd.xml from kubernetes: [Errno 256] No more mirrors to try.
https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/repodata/repomd.xml: [Errno -1] repomd.xml signature could not be verified for kubernetes
[root@master21 ~]#
# 请使用非校验方式执行安装,或者修改Repository中gpgcheck=0再重新安装
[root@master21 ~]# yum install kubeadm-1.23.1 kubelet-1.23.1 kubectl-1.23.1 docker -y --nogpgcheck
....
正在解决依赖关系
--> 正在检查事务
---> 软件包 docker.x86_64.2.1.13.1-209.git7d71120.el7.centos 将被 安装
--> 正在处理依赖关系 docker-common = 2:1.13.1-209.git7d71120.el7.centos,它被软件包 2:docker-1.13.1-209.git7d71120.el7.centos.x86_64 需要
--> 正在处理依赖关系 docker-client = 2:1.13.1-209.git7d71120.el7.centos,它被软件包 2:docker-1.13.1-209.git7d71120.el7.centos.x86_64 需要
--> 正在处理依赖关系
....
[root@master21 ~]#
#安装完成后:
[root@master21 ~]# rpm -qa|grep kube
kubernetes-cni-0.8.7-0.x86_64
kubectl-1.23.1-0.x86_64
kubelet-1.23.1-0.x86_64
kubeadm-1.23.1-0.x86_64
[root@master21 ~]# rpm -qa|grep docker
docker-common-1.13.1-209.git7d71120.el7.centos.x86_64
docker-client-1.13.1-209.git7d71120.el7.centos.x86_64
docker-1.13.1-209.git7d71120.el7.centos.x86_64
[root@master21 ~]# kubectl version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:41:01Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}
The connection to the server localhost:8080 was refused - did you specify the right host or port?
[root@master21 ~]#
#worker,重复上述步骤,不再贴出具体细节8 2个机器分别启动kubelet和docker服务
安装之后,docker和kubelet的服务没有自动启动,需要手工启动,并设置为跟随操作系统启动而自动启动。
systemctl enable docker systemctl start docker systemctl status docker systemctl enable kubelet systemctl start kubelet systemctl status kubelet
开始启动:
#master
[root@master21 ~]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; disabled; vendor preset: disabled)
Active: inactive (dead)
Docs: http://docs.docker.com
[root@master21 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; disabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: inactive (dead)
Docs: https://kubernetes.io/docs/
[root@master21 ~]# systemctl start docker
[root@master21 ~]# systemctl enable docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
[root@master21 ~]# systemctl start kubelet
[root@master21 ~]# systemctl enable kubelet
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
[root@master21 ~]#
#worker,重复上述步骤,不再贴出具体细节9 关于指定docker虚拟网卡地址的情况
⚠️⚠️⚠️💊💊💊启动docker之后,发现这里Docker虚拟网卡地址为:172.18.0.1。这里不再需要手工指定docker网络地址。
[root@master21 ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.18.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
ether 02:42:02:5f:83:97 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens32: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.1.21 netmask 255.255.255.0 broadcast 172.17.1.255
inet6 fe80::250:56ff:fe80:1c41 prefixlen 64 scopeid 0x20<link>
ether 00:50:56:80:1c:41 txqueuelen 1000 (Ethernet)
RX packets 89526 bytes 103270805 (98.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 38131 bytes 3098217 (2.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 36 bytes 2832 (2.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 36 bytes 2832 (2.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@master21 ~]# ⚠️⚠️⚠️💊💊💊但是在有些机器的物理网卡地址和docker虚拟网络地址冲突时,则需要指定docker的虚拟网卡地址。
具体步骤是,设定/etc/docker/daemon.json 为下述内容:
[root@master-node ~]# cat /etc/docker/daemon.json
{
"bip": "172.31.0.1/24"
}
[root@master-node ~]# i然后,重启docker服务。查看网络地址信息如下:
[root@master-node ~]# ifconfig
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.1 netmask 255.255.255.0 broadcast 10.244.0.255
inet6 fe80::a483:f1ff:fe57:bcd6 prefixlen 64 scopeid 0x20<link>
ether a6:83:f1:57:bc:d6 txqueuelen 1000 (Ethernet)
RX packets 28560242 bytes 2303825815 (2.1 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 28284962 bytes 2607086871 (2.4 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.31.0.1 netmask 255.255.255.0 broadcast 0.0.0.0 #指定的docker虚拟网卡地址生效
inet6 fe80::42:d7ff:fed9:4a2b prefixlen 64 scopeid 0x20<link>
ether 02:42:d7:d9:4a:2b txqueuelen 0 (Ethernet)
RX packets 1031 bytes 184211 (179.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 990 bytes 195399 (190.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.10.1.52 netmask 255.255.255.0 broadcast 10.10.1.255
inet6 fe80::f816:3eff:fe0a:e656 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:0a:e6:56 txqueuelen 1000 (Ethernet)
RX packets 509646873 bytes 80631865703 (75.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 370735967 bytes 183719494329 (171.1 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
..... 10 关于启动kubelet服务报错的情况说明
这里在启动kubelet服务后,发现服务报错:
[root@master21 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: activating (auto-restart) (Result: exit-code) since 二 2022-06-14 11:28:13 CST; 4s ago
Docs: https://kubernetes.io/docs/
Process: 2783 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=1/FAILURE)
Main PID: 2783 (code=exited, status=1/FAILURE)
6月 14 11:28:13 master21 systemd[1]: Unit kubelet.service entered failed state.
6月 14 11:28:13 master21 systemd[1]: kubelet.service failed.
[root@master21 ~]#解决办法,暂时略过该错误。等后面kubelet init 初始化之后,kubelet服务会自动拉起来。
因为从kubernetes的官方架构图我们知道,kubelet相当于每个节点上的联络人,此时它们应该在等待master节点的kubeadm发号施令,kubeadm见名知意,类似于kubernetes cluster的总司令。而此时我们还没有初始化cluster呢,自然就无法去给各节点的联络人kubelet下发指令了,所以此时kubelet服务启动之后,过一会儿又自动死掉了。
11 Initialize Kubernetes Master and Setup Default User
该步骤只在主节点执行:不能直接执行kubectl init;
⚠️⚠️⚠️默认会到https://k8s.gcr.io/v1/_ping下载对应的images,而默认情况下,国内机器的网络是无法直接访问的。
解决办法是,指定阿里云的镜像地址:kubeadm init –image-repository registry.aliyuncs.com/google_containers
此外,
⚠️⚠️⚠️此外,我们还需要指定pod的network。否则,创建出来的Kubernetes cluster还是有故障的,如下,cluster组件中的coredns pod报错!!!
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 21m (x10 over 31m) default-scheduler 0/1 nodes are available: 1 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't tolerate.
Normal Scheduled 20m default-scheduler Successfully assigned kube-system/coredns-6d8c4cb4d-nfkvp to master21
Warning FailedCreatePodSandBox 20m kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "c719af249ca09b2c0c1597b0f36ebd50f7e8790abcc81539c7529e14fd0e771a" network for pod "coredns-6d8c4cb4d-nfkvp": networkPlugin cni failed to set up pod "coredns-6d8c4cb4d-nfkvp_kube-system" network: open /run/flannel/subnet.env: no such file or directory
Normal SandboxChanged 5m38s (x464 over 20m) kubelet Pod sandbox changed, it will be killed and re-created.
Warning FailedCreatePodSandBox 38s (x608 over 20m) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to set up sandbox container "5d6735416999f70d47c419c31c6da15699d3987094d6a61c2169efed74b22463" network for pod "coredns-6d8c4cb4d-nfkvp": networkPlugin cni failed to set up pod "coredns-6d8c4cb4d-nfkvp_kube-system" network: open /run/flannel/subnet.env: no such file or directory
[root@master21 ~]#因此,最终的初始化命令是:kubeadm init –image-repository registry.aliyuncs.com/google_containers –pod-network-cidr=10.244.0.0/16
#master
[root@master21 ~]# kubeadm init --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16
I0614 13:54:21.538486 12622 version.go:255] remote version is much newer: v1.24.1; falling back to: stable-1.23
[init] Using Kubernetes version: v1.23.7
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master21] and IPs [10.96.0.1 172.17.1.21]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master21] and IPs [172.17.1.21 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master21] and IPs [172.17.1.21 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 11.015724 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.23" in namespace kube-system with the configuration for the kubelets in the cluster
NOTE: The "kubelet-config-1.23" naming of the kubelet ConfigMap is deprecated. Once the UnversionedKubeletConfigMap feature gate graduates to Beta the default name will become just "kubelet-config". Kubeadm upgrade will handle this transition transparently.
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master21 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master21 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: rehqee.9ghobgn6thqxxhh7
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.17.1.21:6443 --token rehqee.9ghobgn6thqxxhh7 \
--discovery-token-ca-cert-hash sha256:2850c0ae47263395f1641d8d51fd045d43081b197590425a08edba5c87ee8148
[root@master21 ~]# kubectl get all -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system pod/coredns-6d8c4cb4d-2m5j6 0/1 ContainerCreating 0 74s
kube-system pod/coredns-6d8c4cb4d-qm2md 0/1 ContainerCreating 0 74s
kube-system pod/etcd-master21 1/1 Running 0 86s
kube-system pod/kube-apiserver-master21 1/1 Running 0 86s
kube-system pod/kube-controller-manager-master21 1/1 Running 0 85s
kube-system pod/kube-proxy-dgdh9 1/1 Running 0 75s
kube-system pod/kube-scheduler-master21 1/1 Running 0 86s
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 88s
kube-system service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 86s
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-system daemonset.apps/kube-proxy 1 1 1 1 1 kubernetes.io/os=linux 86s
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system deployment.apps/coredns 0/2 2 0 86s
NAMESPACE NAME DESIRED CURRENT READY AGE
kube-system replicaset.apps/coredns-6d8c4cb4d 2 2 0 74s
[root@master21 ~]# 此时,可以看到master节点上的kubelet服务已正常,且,看到从阿里云镜像站点下载的几个images:
[root@master21 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since 二 2022-06-14 13:54:44 CST; 5min ago
Docs: https://kubernetes.io/docs/
Main PID: 13336 (kubelet)
CGroup: /system.slice/kubelet.service
└─13336 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-containe...
6月 14 13:59:45 master21 kubelet[13336]: E0614 13:59:45.899159 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed ...
6月 14 13:59:45 master21 kubelet[13336]: E0614 13:59:45.899250 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/docker.service\": failed t...
6月 14 13:59:55 master21 kubelet[13336]: E0614 13:59:55.936603 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed ...
6月 14 13:59:55 master21 kubelet[13336]: E0614 13:59:55.936693 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/docker.service\": failed t...
6月 14 14:00:05 master21 kubelet[13336]: E0614 14:00:05.976275 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed ...
6月 14 14:00:05 master21 kubelet[13336]: E0614 14:00:05.976369 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/docker.service\": failed t...
6月 14 14:00:16 master21 kubelet[13336]: E0614 14:00:16.011733 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed ...
6月 14 14:00:16 master21 kubelet[13336]: E0614 14:00:16.011829 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/docker.service\": failed t...
6月 14 14:00:26 master21 kubelet[13336]: E0614 14:00:26.050077 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed ...
6月 14 14:00:26 master21 kubelet[13336]: E0614 14:00:26.050166 13336 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/docker.service\": failed t...
Hint: Some lines were ellipsized, use -l to show in full.
[root@master21 ~]#根据提示,配置默认用户:
如果想以非root用户启动kubernetes服务的话,执行:
To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
我这里想直接以root运行kubernetes,所以配置个环境变量到.bash_profile即可。
[root@master21 ~]# cat .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
KUBECONFIG=/etc/kubernetes/admin.conf
export PATH KUBECONFIG
[root@master21 ~]# source .bash_profile 此时,看到master-node上的组件deployment.apps/coredns 的状态还是未正常启动:
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE kube-system deployment.apps/coredns 0/2 2 0 86s
其主要原因是还没有配置Pod的network。从kubeadm init 的执行结果也看到有明确提示:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
根据提示页,我们选择配置Flannel:
- Flannel is an overlay network provider that can be used with Kubernetes.
12 配置pod network
注意:该步骤只在主节点执行。
打开Flannel的GitHub页面:
看到安装命令为:
For Kubernetes v1.17+ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
这里的1个问题就是:https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml我们无法访问,并且该文件配置的内容为:
[root@master21 ~]# cat flannel.yaml
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.14.0
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.14.0
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
[root@master21 ~]# 执行安装:
[root@master21 ~]# kubectl apply -f flannel.yaml Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+ podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created [root@master21 ~]# kubectl get all -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system pod/coredns-6d8c4cb4d-2m5j6 1/1 Running 0 14m kube-system pod/coredns-6d8c4cb4d-qm2md 1/1 Running 0 14m kube-system pod/etcd-master21 1/1 Running 0 14m kube-system pod/kube-apiserver-master21 1/1 Running 0 14m kube-system pod/kube-controller-manager-master21 1/1 Running 0 14m kube-system pod/kube-flannel-ds-9m8xg 1/1 Running 0 12m kube-system pod/kube-proxy-dgdh9 1/1 Running 0 14m kube-system pod/kube-scheduler-master21 1/1 Running 0 14m NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14m kube-system service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 14m NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE kube-system daemonset.apps/kube-flannel-ds 1 1 1 1 1 <none> 12m kube-system daemonset.apps/kube-proxy 1 1 1 1 1 kubernetes.io/os=linux 14m NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE kube-system deployment.apps/coredns 2/2 2 2 14m NAMESPACE NAME DESIRED CURRENT READY AGE kube-system replicaset.apps/coredns-6d8c4cb4d 2 2 2 14m [root@master21 ~]# ll /run/flannel/ 总用量 4 -rw-r--r-- 1 root root 96 6月 14 13:56 subnet.env [root@master21 ~]#
至此,看到cluster节点上的各种组件已经全部正常了: deployment.apps/coredns 2/2 。
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE kube-system deployment.apps/coredns 2/2 2 2 33m
且,master 节点上生成了/run/flannel/subnet.env。我们可以查看其中的内容:
[root@master21 ~]# cat /run/flannel/subnet.env FLANNEL_NETWORK=10.244.0.0/16 FLANNEL_SUBNET=10.244.0.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true [root@master21 ~]#
其实,就是我们在初始化节点时指定的pod network信息。
13 添加worker节点
Join the Worker Node to the Kubernetes Cluster
根据前面步骤11中的提示,只在worker节点上执行:
[root@worker22 ~]# kubeadm join 172.17.1.21:6443 --token mpx0co.zfmcpq5bmxv6kwo9 --discovery-token-ca-cert-hash sha256:053cf0248391bb5e9ea3acd7a9060ec70484978783bdd05b49ed1480b042cddf
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
[root@worker22 ~]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since 二 2022-06-14 14:11:20 CST; 2min 17s ago
Docs: https://kubernetes.io/docs/
Main PID: 950 (kubelet)
CGroup: /system.slice/kubelet.service
└─950 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --network-plugin=cni --pod-infra-container-...
6月 14 14:12:02 worker22 kubelet[950]: E0614 14:12:02.244231 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:12:12 worker22 kubelet[950]: E0614 14:12:12.268339 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:12:22 worker22 kubelet[950]: E0614 14:12:22.296143 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:12:32 worker22 kubelet[950]: E0614 14:12:32.318708 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:12:42 worker22 kubelet[950]: E0614 14:12:42.345883 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:12:52 worker22 kubelet[950]: E0614 14:12:52.370792 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:13:02 worker22 kubelet[950]: E0614 14:13:02.395268 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:13:12 worker22 kubelet[950]: E0614 14:13:12.419081 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:13:22 worker22 kubelet[950]: E0614 14:13:22.443750 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
6月 14 14:13:32 worker22 kubelet[950]: E0614 14:13:32.471274 950 summary_sys_containers.go:48] "Failed to get system container stats" err="failed to get cgroup stats for \"/system.slice/kubelet.service\": failed to...
Hint: Some lines were ellipsized, use -l to show in full.
[root@worker22 ~]# 添加之后,看到worker节点上的kubectl服务自动成功运行了。且也生成了/run/flannel/subnet.env 文件。
稍等片刻,可以从主节点上看到节点状态全部正常:
[root@master21 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master21 Ready control-plane,master 14m v1.23.1 worker22 Ready <none> 2m v1.23.1 [root@master21 ~]#
14 master安装配置bash-completion
[root@master21 ~]# yum install bash-completion 已加载插件:fastestmirror, product-id, search-disabled-repos, subscription-manager This system is not registered with an entitlement server. You can use subscription-manager to register. Loading mirror speeds from cached hostfile * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com 正在解决依赖关系 --> 正在检查事务 ---> 软件包 bash-completion.noarch.1.2.1-8.el7 将被 安装 --> 解决依赖关系完成 依赖关系解决 ============================================================================================================================================================================================================================== Package 架构 版本 源 大小 ============================================================================================================================================================================================================================== 正在安装: bash-completion noarch 1:2.1-8.el7 base 87 k 事务概要 ============================================================================================================================================================================================================================== 安装 1 软件包 总下载量:87 k 安装大小:263 k Is this ok [y/d/N]: y Downloading packages: bash-completion-2.1-8.el7.noarch.rpm | 87 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction 正在安装 : 1:bash-completion-2.1-8.el7.noarch 1/1 验证中 : 1:bash-completion-2.1-8.el7.noarch 1/1 已安装: bash-completion.noarch 1:2.1-8.el7 完毕! [root@master21 ~]#
然后,在root的~/.bash_profile里添加:source <(kubectl completion bash)
source <(kubectl completion bash)
三 测试验证cluster
1创建NGINX Deployment
[root@master21 ~]# kubectl create deployment nginx --image=nginx deployment.apps/nginx created [root@master21 ~]#
2 创建nodeport类型 servier
[root@master21 ~]# kubectl create service nodeport nginx --tcp=80:80 service/nginx created [root@master21 ~]#
3 通过service对象访问
[root@master21 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23m nginx NodePort 10.103.226.90 <none> 80:30537/TCP 9s [root@master21 ~]#
客户端通过NodePort类型的service访问,即访问cluster中任意机器的IP+端口(30537):
asher at MacBook-Air-3 in ~
$ curl 172.17.1.21:30537
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
asher at MacBook-Air-3 in ~
$ NGINX服务正常,说明cluster是OK的。
4 删除测试的Deployment和service对象
[root@master21 ~]# kubectl delete deployments.apps nginx deployment.apps "nginx" deleted [root@master21 ~]# kubectl delete service nginx service "nginx" deleted [root@master21 ~]#
四 小结和链接
kubernetes功能强大,知识体系比较多。但,不要紧,万事开头难,从成功的安装和配置开始迈出第一步。
How to Install a Kubernetes Cluster on CentOS 7
在kubernetes cluster上部署NGINX服务流程及错误解决
说明,本文档是一次性安装成功的版本。之前,也在CentOS 7上安装过Kubernetes cluster,但是那个文档记录的有遇到具体的错误,并且如何解决的版本。具体可见: