Kubernetes in Action读书笔记第六章:Volume
本章主要内容
为什么我们需要volume
volume的主要作用
volume和pod,container之前的关系;
创建1个包含多个container的pod,通过volume实现container共享数据;
了解emptyDir和hostPath、gitRepo的场景;
通过NFS来实现持久化存储;
PV和PVC的作用以及如何使用;
Contents
1 为什么我们需要volume
pod中的container写的数据不能持久化,如果container重启之后,看不到之前写的数据,怎么处理?
无法解决多个container想共享访问同一份数据的场景;
pod出现故障之后,被调度到其它node上重新运行之后,如何保证它还可以访问到之前读写的数据?
container中的进程看到的文件系统源于构建这个container的image时的文件系统,也就是说,即使是运行在同一个pod中的多个container,它们彼此看到的文件系统是不同的。
另外,运行在pod中的container如果出现重启,那么新启动的container是看不到之前的container对文件系统的修改。这很不好,在某些场景下,我们当然希望pod中的container重启之后,它依然可以看到之前的container对文件所做的修改。
于是,人们搞出了一个被叫做volume的资源对象,它的作用就是为pod提供持久化存储的。
2 volume的作用
为pod提供持久化存储,即使pod reschedule到其它node上继续运行,依然可以保证它里面的container可以继续读写它在被重新调度之前读写的数据;
也为多个container共享访问同一份数据,提供了支持;
3 volume和pod、container之间的关系
volume并不是一个独立的资源对象,它是被定义在pod里的一部分,同时它的生命周期也跟pod一样,pod如果停止,volume也随之消失。volume不可以单独创建,也不可以单独删除。
同一个pod里定义的volume可以被该pod中的多个container共享访问,只是需要这多个container分别把该volume挂载上去,当然不同的container可以将同一个volume挂载到不同的路径下。
1个volume只能位于1个pod之中;1个pod却可以定义多个volume;
pod中的volume的创建和初始化早于pod中container的创建和初始化;
4 使用volume解决1个pod中多个container共享数据的场景
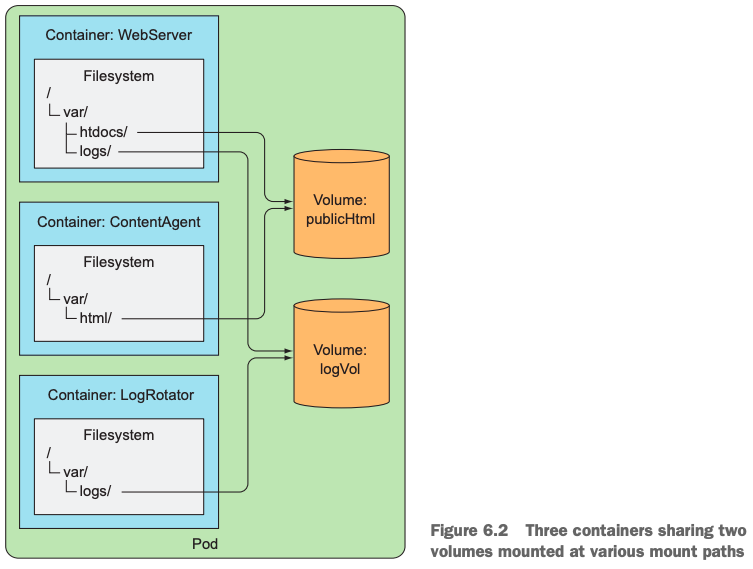
假定有1个pod中分别运行了3个container:
- WebServer提供web服务的,它需要读取解析/var/htdocs/ 路径下的页面文件,对外服务,同时,它要记录日志到/var/logs路径下;
- ContentAgent生成页面文件,并存放到/var/html路径下;
- LogRotator定期读取/var/logs下的日志文件,并对日志文件进行压缩,rotate(周期回写)操作。
如果没有volume的话,这3个container是无法看到彼此容器中的文件的:
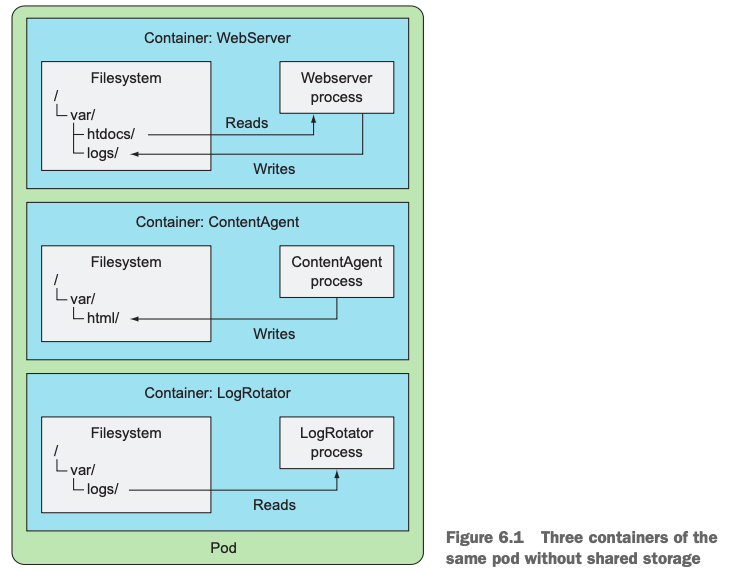
与之对应的,如果我们采用了volume的话,则问题得到完美解决,在pod中定义2个不同的volume,然后把它们分别挂载到3个不同的container中:
publicHtml分别挂载到ContentAgent的/var/html路径下,它可以向该路径直接生成文件;同时该volume也挂载到WebServer的/var/htdocs路径下,ContentAgent写的web文件,它就可以直接读取了;
logVol分别挂载到LogRotator和WebServer的同一个路径下/var/logs,这样LogRotator就可以读取WebServer向该volume中的写的数据了。
5 在pod中定义和使用volume的流程和思路
pod的spec字段里先定义volume字段,并且指定volume的名字和类型;然后再在pod的spec.container字段里定义1个volumeMounts字段,让其指向前面定义的那个volume,这样container就可以使用这个volume了。
6 volume的分类
常见的volume类型有emptyDir,hostPath,gitRepo,configMap、downwardAPI等。
https://kubernetes.io/docs/concepts/storage/volumes/
7 创建和使用emptyDir类型的volume来实现1个pod中多个container共享数据的场景
7.0 适合emptyDir的场景
- scratch space, such as for a disk-based merge sort
- checkpointing a long computation for recovery from crashes
- holding files that a content-manager container fetches while a webserver container serves the data
7.1场景说明
创建1个包含2个container的pod,其中1个container通过调用系统的fortune命令负责写web的HTML页面文件,每间隔10s写1个新的web页面;第2个container运行NGINX web server,把第1个container写的HTML页面展示给客户端;
7.2 准备html-generator的image
下述操作均在172.16.11.36机器执行
生成HTML web页面的脚本,fortuneloop.sh
#!/bin/bash trap "exit" SIGINT mkdir /var/htdocs while : do echo $(date) Writing fortune to /var/htdocs/index.html /usr/games/fortune > /var/htdocs/index.html sleep 10 done
构建fortune这个image的Dockerfile:
FROM ubuntu:latest RUN apt-get update;apt-get -y install fortune ADD fortuneloop.sh /bin/fortuneloop.sh ENTRYPOINT /bin/fortuneloop.sh
创建fortune路径,并把上述2个文件放到该路径下:
[root@centos-master fortune]# pwd /root/fortune [root@centos-master fortune]# ls -l 总用量 8 -rw-r--r-- 1 root root 135 3月 19 23:08 Dockerfile -rw-r--r-- 1 root root 186 3月 19 23:07 fortuneloop.sh [root@centos-master fortune]#
构建image:
[root@centos-master fortune]# docker build -t renguzi/fortune . Sending build context to Docker daemon 3.072 kB Step 1/4 : FROM ubuntu:latest Trying to pull repository docker.io/library/ubuntu ... latest: Pulling from docker.io/library/ubuntu 4d32b49e2995: Downloading [==================> ] 10.62 MB/28.57 MB ... Processing triggers for libc-bin (2.31-0ubuntu9.7) ... ---> 02095818d482 Removing intermediate container c0c78945fed1 Step 3/4 : ADD fortuneloop.sh /bin/fortuneloop.sh ---> b4e5c635ac92 Removing intermediate container c3e695b17918 Step 4/4 : ENTRYPOINT /bin/fortuneloop.sh ---> Running in 6d7e9f2085c8 ---> aa29dc760e5c Removing intermediate container 6d7e9f2085c8 Successfully built aa29dc760e5c [root@centos-master fortune]# docker images|grep fortune renguzi/fortune latest aa29dc760e5c About a minute ago 109 MB [root@centos-master fortune]#
构建过程中,出现过几次错误,重试几次又可以了,莫名其妙的网络问题:
W: Failed to fetch http://archive.ubuntu.com/ubuntu/dists/focal/InRelease Connection failed [IP: 91.189.88.142 80] W: Failed to fetch http://archive.ubuntu.com/ubuntu/dists/focal-updates/InRelease Connection failed [IP: 91.189.88.152 80] W: Failed to fetch http://archive.ubuntu.com/ubuntu/dists/focal-backports/InRelease Connection failed [IP: 91.189.88.142 80] W: Failed to fetch http://security.ubuntu.com/ubuntu/dists/focal-security/InRelease Connection failed [IP: 91.189.91.39 80] W: Some index files failed to download. They have been ignored, or old ones used instead. Reading package lists... Building dependency tree... Reading state information... E: Unable to locate package fortune The command '/bin/sh -c apt-get update;apt-get -y install fortune' returned a non-zero code: 100 [root@centos-master fortune]#
push image到Docker hub:
[root@centos-master fortune]# docker push renguzi/fortune The push refers to a repository [docker.io/renguzi/fortune] 1c1967619c72: Pushed 670492affb8f: Pushed 867d0767a47c: Mounted from library/ubuntu latest: digest: sha256:c4c0960d79cb1ac24a187d51669fa60da034bdc1e87d9c36a1462f8972219828 size: 948 [root@centos-master fortune]#
7.3 准备pod的yaml
Kubernetes master节点执行:
新建/root/my-fortune/fortune-pod.yaml文件,内容如下:
apiVersion: v1
kind: Pod
metadata:
name: fortune #pod的名字
labels:
vol: empty-dir #给pod贴上标签
spec:
containers:
- image: renguzi/fortune #第一个container的image,前面准备好的
name: html-generator
volumeMounts: #步骤2: container使用volume的挂载配置,其实引用的就是步骤1中配置的volume的名字
- name: html
mountPath: /var/htdocs
- image: nginx:alpine
name: web-server
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html #container使用volume的挂载配置
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes: #步骤1: pod中声明volume配置的字段;
- name: html #声明volume的名字
emptyDir: {} #volume的类型7.4 创建pod
[root@master-node my-fortune]# kubectl apply -f fortune-pod.yaml pod/fortune created [root@master-node my-fortune]# kubectl get pods -owide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS fortune 2/2 Running 0 29s 10.244.2.205 node-2 <none> <none> vol=empty-dir kubia-4mwx6 1/1 Running 0 5d21h 10.244.2.198 node-2 <none> <none> app=kubia kubia-htskq 1/1 Running 0 5d21h 10.244.2.199 node-2 <none> <none> app=kubia kubia-nt72z 1/1 Running 0 5d21h 10.244.1.20 node-1 <none> <none> app=kubia [root@master-node ~]#
7.5创建1个Service对象
[root@master-node my-fortune]# cat fortune-service.yaml
apiVersion: v1
kind: Service #类型为Service资源对象
metadata:
name: fortune-service #Service名为库表
spec:
ports:
- port: 80 #Service对外提供的端口是80
targetPort: 80 #Pod端口是80
selector:
vol: empty-dir
[root@master-node my-fortune]# kubectl apply -f fortune-service.yaml
service/fortune-service created
[root@master-node my-fortune]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
fortune-service ClusterIP 10.105.28.42 <none> 80/TCP 7s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20d
kubia ClusterIP 10.101.149.183 <none> 80/TCP 5d21h
kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 5d18h
[root@master-node ~]#7.6访问Service来验证
[root@master-node my-fortune]# curl http://10.105.28.42
Behold, the fool saith, "Put not all thine eggs in the one basket"--which is
but a manner of saying, "Scatter your money and your attention;" but the wise
man saith, "Put all your eggs in the one basket and--WATCH THAT BASKET."
-- Mark Twain, "Pudd'nhead Wilson's Calendar"
[root@master-node my-fortune]#
[root@master-node ~]# curl http://10.105.28.42
I got a hint of things to come when I overheard my boss lamenting, 'The
books are done and we still don't have an author! I must sign someone
today!
-- Tamim Ansary, "Edutopia Magazine, Issue 2, November 2004"
on the topic of school textbooks
[root@master-node my-fortune]# 至此,我们可以看到通过Service资源访问时,后端的web-server这个container (nginx)给我们返回了不同的页面信息,因为它读取的是另外一个container(html-generator)生成的页面文件。而这2个container是运行在同一个pod中,挂载了同一个volume,进而实现了多个container共享数据。
其实,emptyDir的volume其实底层使用的存储是由pod所在node的文件系统提供的存储。我们如果想要提高其性能的话,可以把它的媒介属性指向内存。如,在pod的volume字段里这样定义:
volumes:
- name: html
emptyDir:
medium: Memory #则该volume的数据将存在pod所在节点的内存中,其实只是使用了tmpfs类型的文件系统Depending on your environment,
emptyDirvolumes are stored on whatever medium that backs the node such as disk or SSD, or network storage. However, if you set theemptyDir.mediumfield to"Memory", Kubernetes mounts a tmpfs (RAM-backed filesystem) for you instead. While tmpfs is very fast, be aware that unlike disks, tmpfs is cleared on node reboot and any files you write count against your container’s memory limit.
https://kubernetes.io/docs/concepts/storage/volumes/#emptydir
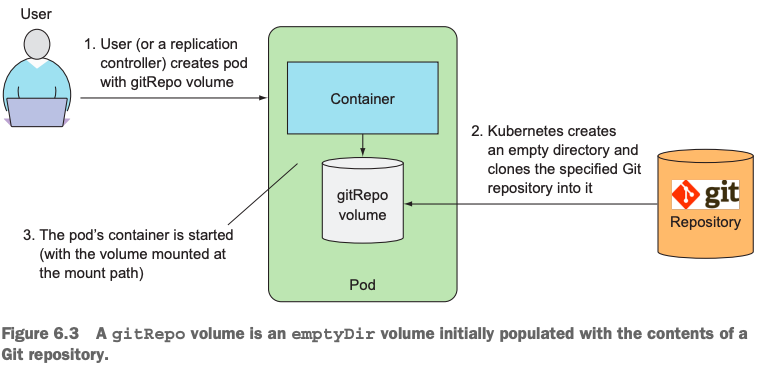
8 创建和使用gitRepo类型的volume
8.1 gitRepo的本质和流程
和emptyDir类型的volume类似,只是gitRepo类型的存储本质是把远端一个GitHub的Repository地址当作volume声明在pod里,然后把该Repository clone到运行该pod的node上,最后该pod里的container会读取该Repository里的所有文件。
注意,一旦clone GitHub Repository到本地node上,pod运行起来,container读取本地里的文件之后,远端Repository里的文件发生变更提交,本地是不能实时同步更新感知远端文件发生变化的。
其流程如下:
8.2 gitRepo应用场景
用于读取远端仓库里的文件作为静态站点内容。实用性不是很高。
8.3 gitRepo创建案例
yaml文件,gitrepo-volume-pod.yaml :
[root@master-node Chapter06]# pwd
/root/kubernetes-in-action/Chapter06
[root@master-node Chapter06]# cat gitrepo-volume-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: gitrepo-volume-pod
spec:
containers:
- image: nginx:alpine
name: web-server
volumeMounts: #步骤2,配置VolumeMounts字段,指向gitRepo声明的volume
- name: html
mountPath: /usr/share/nginx/html #挂载到container里的路径
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
gitRepo: #步骤1 声明volume类型为gitRepo
repository: https://github.com/luksa/kubia-website-example.git #远端仓库地址
revision: master #clone远端仓库地址时,选取哪个版本
directory: . #这里的dot表示读取远端仓库地址到本地volume的根路径下
[root@master-node Chapter06]# 创建带有gitRepo volume的pod,并验证访问:
[root@master-node Chapter06]# kubectl apply -f gitrepo-volume-pod.yaml Warning: spec.volumes[0].gitRepo: deprecated in v1.11 pod/gitrepo-volume-pod created [root@master-node ~]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES fortune 2/2 Running 0 18m 10.244.2.207 node-2 <none> <none> gitrepo-volume-pod 1/1 Running 0 5m36s 10.244.2.208 node-2 <none> <none> kubia-4mwx6 1/1 Running 0 6d5h 10.244.2.198 node-2 <none> <none> kubia-htskq 1/1 Running 0 6d5h 10.244.2.199 node-2 <none> <none> kubia-nt72z 1/1 Running 0 6d5h 10.244.1.20 node-1 <none> <none> [root@master-node ~]# curl 10.244.2.208 <html> <body> Hello there. </body> </html> [root@master-node ~]#
9 查看和了解hostPath类型的volume
9.1为什么需要hostPath类型的volume
前面的emptyDir和gitRepo类型的volume,都不是持久化的存储,当pod消失,该类型volume里的数据也随之消失。而hostPath却是可以提供持久化存储的一种volume。只是从实用性来讲,通常还是把hostPath当作pod去读取其所在node的文件系统上的文件的内容来用。至于真正的持久化存储,还有其它类型的volume。
应用场景,通常用于那些收集node机器上的日志的pod,或者是DaemonSet类型的控制器使用该类型的volume。
9.2 hostPath volume的原理和步骤
首先,在pod的volume字段里声明一个volume,其类型为HostPath,并且指定路径为node上实际存在的路径。然后,再在pod中关于container字段里的Mounts字段上指定要在容器里的哪个路径下,挂载前面声明的HostPath类型的volume。
比如,Kubernetes cluster的kube-system namespace里就有很多pod使用该类型的volume:
[root@master-node Chapter06]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-6d8c4cb4d-2shsn 1/1 Running 0 72d coredns-6d8c4cb4d-nnbxg 1/1 Running 0 72d etcd-master-node 1/1 Running 4 (52d ago) 72d kube-apiserver-master-node 1/1 Running 53 (38d ago) 72d kube-controller-manager-master-node 1/1 Running 526 (19h ago) 72d kube-flannel-ds-764mr 1/1 Running 0 72d kube-flannel-ds-wwfj8 1/1 Running 2 (24d ago) 72d kube-flannel-ds-x5r9x 1/1 Running 0 72d kube-proxy-7m24h 1/1 Running 1 (24d ago) 72d kube-proxy-cpq5w 1/1 Running 0 72d kube-proxy-sm5px 1/1 Running 0 72d kube-scheduler-master-node 1/1 Running 495 (19h ago) 72d [root@master-node Chapter06]#
这里选取kube-system namespace里的etcd-master-node pod来查看它是如何使用HostPath volume的:
[root@master-node Chapter06]# kubectl describe pod -n kube-system etcd-master-node
Name: etcd-master-node
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: master-node/172.16.11.168
Start Time: Fri, 07 Jan 2022 17:11:49 +0800
...
Controlled By: Node/master-node
Containers:
etcd:
...
Mounts:
/etc/kubernetes/pki/etcd from etcd-certs (rw) #2 将步骤1里的路径挂载到container上去
/var/lib/etcd from etcd-data (rw)
...
Volumes:
etcd-certs:
Type: HostPath (bare host directory volume) #1 指定volume类型是HostPath
Path: /etc/kubernetes/pki/etcd #指定该路径在node上的真实路径
HostPathType: DirectoryOrCreate
etcd-data:
Type: HostPath (bare host directory volume)
Path: /var/lib/etcd
HostPathType: DirectoryOrCreate
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: :NoExecute op=Exists
Events: <none>
[root@master-node Chapter06]#
#查看主机上对应的真实路径
[root@master-node Chapter06]# ll /etc/kubernetes/pki/etcd/
总用量 32
-rw-r--r-- 1 root root 1086 1月 7 17:11 ca.crt
-rw------- 1 root root 1679 1月 7 17:11 ca.key
-rw-r--r-- 1 root root 1159 1月 7 17:11 healthcheck-client.crt
-rw------- 1 root root 1679 1月 7 17:11 healthcheck-client.key
-rw-r--r-- 1 root root 1204 1月 7 17:11 peer.crt
-rw------- 1 root root 1675 1月 7 17:11 peer.key
-rw-r--r-- 1 root root 1204 1月 7 17:11 server.crt
-rw------- 1 root root 1675 1月 7 17:11 server.key
[root@master-node Chapter06]# ll /var/lib/etcd/
总用量 0
drwx------ 4 root root 29 1月 27 06:46 member
[root@master-node Chapter06]#10 通过NFS来创建持久化存储的pod
10.1 先创建配置NFS服务端
CentOS 7/RHEL7上安装配置和使用NFS参考:https://www.howtoforge.com/nfs-server-and-client-on-centos-7
这里选择另外一台机器172.16.17.7作为NFS服务端,然后我们的Kubernetes cluster中的3个节点分别挂载该nfs server上的存储到本地。
#1 当前机器/根文件系统还有存储空间可用,新建mkdir -p /data/nfs用作网络存储
[root@guoxin7 ~]# df -Th -x overlay -x tmpfs
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 20G 0 20G 0% /dev
/dev/mapper/centos-root xfs 112G 66G 46G 60% /
/dev/sda1 xfs 1014M 230M 785M 23% /boot
[root@guoxin7 ~]# mkdir -p /data/nfs
[root@guoxin7 ~]# chmod -R 755 /data/nfs
[root@guoxin7 ~]# yum install nfs-utils -y
...
作为依赖被安装:
gssproxy.x86_64 0:0.7.0-30.el7_9 keyutils.x86_64 0:1.5.8-3.el7 libbasicobjects.x86_64 0:0.1.1-32.el7 libcollection.x86_64 0:0.7.0-32.el7 libevent.x86_64 0:2.0.21-4.el7
libini_config.x86_64 0:1.3.1-32.el7 libnfsidmap.x86_64 0:0.25-19.el7 libpath_utils.x86_64 0:0.2.1-32.el7 libref_array.x86_64 0:0.1.5-32.el7 libtirpc.x86_64 0:0.2.4-0.16.el7
libverto-libevent.x86_64 0:0.2.5-4.el7 quota.x86_64 1:4.01-19.el7 quota-nls.noarch 1:4.01-19.el7 rpcbind.x86_64 0:0.2.0-49.el7 tcp_wrappers.x86_64 0:7.6-77.el7
完毕!
[root@guoxin7 ~]# id nfsnobody
uid=65534(nfsnobody) gid=65534(nfsnobody) 组=65534(nfsnobody)
[root@guoxin7 ~]# chown -R nfsnobody:nfsnobody /data/nfs/
#2 设置配置文件
[root@guoxin7 ~]# cat /etc/exports
/data/nfs 172.16.11.168(rw,sync,no_root_squash,no_all_squash)
/data/nfs 172.16.11.161(rw,sync,no_root_squash,no_all_squash)
/data/nfs 172.16.11.148(rw,sync,no_root_squash,no_all_squash)
[root@guoxin7 ~]#
#3 启动服务
systemctl enable rpcbind
systemctl enable nfs-server
systemctl start rpcbind
systemctl start nfs-server
systemctl status rpcbind
systemctl status nfs-server
[root@guoxin7 ~]# systemctl enable rpcbind
[root@guoxin7 ~]# systemctl enable nfs-server
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
[root@guoxin7 ~]# systemctl start rpcbind
[root@guoxin7 ~]# systemctl start nfs-server
[root@guoxin7 ~]# systemctl status rpcbind
● rpcbind.service - RPC bind service
Loaded: loaded (/usr/lib/systemd/system/rpcbind.service; enabled; vendor preset: enabled)
Active: active (running) since 五 2022-03-25 16:58:55 CST; 15s ago
Process: 17121 ExecStart=/sbin/rpcbind -w $RPCBIND_ARGS (code=exited, status=0/SUCCESS)
Main PID: 17122 (rpcbind)
CGroup: /system.slice/rpcbind.service
└─17122 /sbin/rpcbind -w
3月 25 16:58:55 guoxin7 systemd[1]: Starting RPC bind service...
3月 25 16:58:55 guoxin7 systemd[1]: Started RPC bind service.
[root@guoxin7 ~]# systemctl status nfs-server
● nfs-server.service - NFS server and services
Loaded: loaded (/usr/lib/systemd/system/nfs-server.service; enabled; vendor preset: disabled)
Drop-In: /run/systemd/generator/nfs-server.service.d
└─order-with-mounts.conf
Active: active (exited) since 五 2022-03-25 16:59:04 CST; 12s ago
Process: 17200 ExecStartPost=/bin/sh -c if systemctl -q is-active gssproxy; then systemctl reload gssproxy ; fi (code=exited, status=0/SUCCESS)
Process: 17182 ExecStart=/usr/sbin/rpc.nfsd $RPCNFSDARGS (code=exited, status=0/SUCCESS)
Process: 17180 ExecStartPre=/usr/sbin/exportfs -r (code=exited, status=0/SUCCESS)
Main PID: 17182 (code=exited, status=0/SUCCESS)
CGroup: /system.slice/nfs-server.service
3月 25 16:59:03 guoxin7 systemd[1]: Starting NFS server and services...
3月 25 16:59:04 guoxin7 systemd[1]: Started NFS server and services.
[root@guoxin7 ~]# 10.2 NFS客户端机器安装nfs-utils工具
172.16.11.168、172.16.11.161、172.16.11.148分别执行下述命令:
#1 yum install nfs-utils -y 必须执行 #2 mkdir -p /data/db 非必须 #3 mount -t nfs 172.16.17.7:/data/nfs /data/db 非必须 [root@node-2 ~]# yum install nfs-utils -y 已加载插件:fastestmirror, product-id, search-disabled-repos, subscription-manager ... [root@node-2 ~]# mkdir -p /data/db [root@node-2 ~]# mount -t nfs 172.16.17.7:/data/nfs /data/db [root@node-2 ~]# df -Th -x overlay -x tmpfs 文件系统 类型 容量 已用 可用 已用% 挂载点 /dev/mapper/centos-root xfs 791G 65G 726G 9% / devtmpfs devtmpfs 3.9G 0 3.9G 0% /dev /dev/sda1 xfs 1014M 142M 873M 14% /boot 172.16.17.7:/data/nfs nfs4 112G 67G 45G 60% /data/db [root@node-2 ~]#
10.3 启动使用NFS volume的pod
[root@master-node Chapter06]# cat mongodb-pod-nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: mongodb-nfs
spec:
volumes:
- name: mongodb-data
nfs:
server: 172.16.17.7 #指定NFS服务器信息
path: /data/nfs #NFS服务器输出的存储路径
containers:
- image: mongo
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db #NFS server172.16.17.7的/data/nfs被挂载到container中的路径
ports:
- containerPort: 27017
protocol: TCP
[root@master-node Chapter06]#
[root@master-node Chapter06]# kubectl apply -f mongodb-pod-nfs.yaml
pod/mongodb-nfs created
[root@master-node Chapter06]# kubectl get pods mongodb-nfs
NAME READY STATUS RESTARTS AGE
mongodb-nfs 1/1 Running 0 23m
[root@master-node Chapter06]# 创建pod之后,发现一切正常。且在3个机器上,每个机器的/data/db路径下的内容都相同。
[root@node-1 ~]# ll /data/db/ -lrt 总用量 352 -rw-r--r-- 1 polkitd root 0 3月 25 17:10 a -rw------- 1 polkitd input 50 3月 25 17:24 WiredTiger -rw------- 1 polkitd input 21 3月 25 17:24 WiredTiger.lock -rw------- 1 polkitd input 4096 3月 25 17:24 WiredTigerHS.wt -rw------- 1 polkitd input 2 3月 25 17:24 mongod.lock -rw------- 1 polkitd input 114 3月 25 17:24 storage.bson drwx------ 2 polkitd input 110 3月 25 17:24 journal -rw------- 1 polkitd input 20480 3月 25 17:25 index-3-2165911872485014331.wt -rw------- 1 polkitd input 20480 3月 25 17:25 collection-2-2165911872485014331.wt -rw------- 1 polkitd input 20480 3月 25 17:25 index-1-2165911872485014331.wt -rw------- 1 polkitd input 20480 3月 25 17:25 collection-0-2165911872485014331.wt -rw------- 1 polkitd input 20480 3月 28 10:58 index-8-2165911872485014331.wt -rw------- 1 polkitd input 20480 3月 28 10:58 collection-7-2165911872485014331.wt -rw------- 1 polkitd input 36864 3月 28 10:58 _mdb_catalog.wt -rw------- 1 polkitd input 20480 3月 28 10:59 index-6-2165911872485014331.wt -rw------- 1 polkitd input 20480 3月 28 10:59 index-5-2165911872485014331.wt -rw------- 1 polkitd input 20480 3月 28 10:59 collection-4-2165911872485014331.wt -rw------- 1 polkitd input 36864 3月 28 10:59 sizeStorer.wt -rw------- 1 polkitd input 77824 3月 28 10:59 WiredTiger.wt -rw------- 1 polkitd input 1482 3月 28 10:59 WiredTiger.turtle drwx------ 2 polkitd input 113 3月 28 11:00 diagnostic.data [root@node-1 ~]#
注意:如果前面10.2步骤中,不在每个节点上安装nfs-utils工具的话,那么这里启动pod的时候,可能会遇到类似下述错误:
[root@master-node Chapter06]# kubectl describe pod mongodb-nfs
Name: mongodb-nfs
....
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 15m default-scheduler Successfully assigned default/mongodb-nfs to node-2
Warning FailedMount 4m1s (x2 over 10m) kubelet Unable to attach or mount volumes: unmounted volumes=[mongodb-data], unattached volumes=[mongodb-data kube-api-access-9zw7x]: timed out waiting for the condition
Warning FailedMount 2m46s (x14 over 15m) kubelet MountVolume.SetUp failed for volume "mongodb-data" : mount failed: exit status 32
Mounting command: mount
Mounting arguments: -t nfs 172.16.17.7:/data/nfs /var/lib/kubelet/pods/a6d54c3f-b9f3-4f55-9b9b-467a8fd83200/volumes/kubernetes.io~nfs/mongodb-data
Output: mount: 文件系统类型错误、选项错误、172.16.17.7:/data/nfs 上有坏超级块、
缺少代码页或助手程序,或其他错误
(对某些文件系统(如 nfs、cifs) 您可能需要
一款 /sbin/mount.<类型> 助手程序)
有些情况下在 syslog 中可以找到一些有用信息- 请尝试
dmesg | tail 这样的命令看看。
Warning FailedMount 106s (x4 over 13m) kubelet Unable to attach or mount volumes: unmounted volumes=[mongodb-data], unattached volumes=[kube-api-access-9zw7x mongodb-data]: timed out waiting for the condition
Normal Pulling 40s kubelet Pulling image "mongo"这个错误有误导,不是NFS server 172.16.17.7:/data/nfs 上有坏超级块,而是NFS客户端机器(kubernertes 的worker node)上没有安装nfs-utils工具导致的。为什么呢?因为container里的挂载依赖于包含它的pod所在worker node机器来执行挂载的,然后再在容器内把worker node挂载的存储再映射进去的。比如,pod运行在node-2节点上,我们从node-2节点上看到,下述挂载信息:
[root@node-2 ~]# df -Th|grep nfs4 172.16.17.7:/data/nfs nfs4 112G 67G 45G 60% /var/lib/kubelet/pods/b289ee92-385c-4e1f-81cd-5e56575712ff/volumes/kubernetes.io~nfs/mongodb-data [root@node-2 ~]# docker ps|grep mongo cac28e283d23 1f72653971e5 "docker-entrypoint..." 19 minutes ago Up 18 minutes k8s_mongodb_mongodb-nfs_default_b289ee92-385c-4e1f-81cd-5e56575712ff_0 28322f45e9d7 registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 19 minutes ago Up 18 minutes k8s_POD_mongodb-nfs_default_b289ee92-385c-4e1f-81cd-5e56575712ff_0 [root@node-2 ~]# docker exec -it cac28e283d23 /bin/bash root@mongodb-nfs:/# hostname mongodb-nfs root@mongodb-nfs:/# df -Th Filesystem Type Size Used Avail Use% Mounted on overlay overlay 791G 66G 726G 9% / tmpfs tmpfs 3.9G 0 3.9G 0% /dev tmpfs tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup /dev/mapper/centos-root xfs 791G 66G 726G 9% /etc/hosts 172.16.17.7:/data/nfs nfs4 112G 67G 45G 60% /data/db shm tmpfs 64M 0 64M 0% /dev/shm tmpfs tmpfs 7.6G 12K 7.6G 1% /run/secrets/kubernetes.io/serviceaccount tmpfs tmpfs 3.9G 0 3.9G 0% /proc/acpi tmpfs tmpfs 3.9G 0 3.9G 0% /proc/scsi tmpfs tmpfs 3.9G 0 3.9G 0% /sys/firmware root@mongodb-nfs:/#
从上,我们可以从container内部再看到映射的挂载信息。
10.4 进入MongoDB写数据
kubectl exec -it mongodb-nfs — /bin/bash 进入pod内部,执行/bin/bash命令,执行mongo客户端交互式命令连接到MongoDB数据库,执行插入数据操作:
[root@master-node ~]# kubectl exec -it mongodb-nfs -- /bin/bash
root@mongodb-nfs:/# mongo
...
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
> use mydb;
switched to db mydb
> db.collection1.insert({volumeType:'NFS'});
WriteResult({ "nInserted" : 1 })
> db.collection1.find();
{ "_id" : ObjectId("6241244f113eead6c908fbda"), "volumeType" : "NFS" }
> 10.5 重启使用nfs volume的pod
mongodb-nfs这个pod,当前运行在node-2上,我们手动杀掉该pod,并修改其node selector,使其运行在node-1上。目的就是为了验证采用NFS volume的pod,不管调度到哪个node上,都可以重新读取前一个pod所写的数据。
[root@master-node Chapter06]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE fortune 2/2 Running 0 7d18h 10.244.2.207 node-2 gitrepo-volume-pod 1/1 Running 0 7d18h 10.244.2.208 node-2 kubia-4mwx6 1/1 Running 0 13d 10.244.2.198 node-2 kubia-htskq 1/1 Running 0 13d 10.244.2.199 node-2 kubia-manual 1/1 Running 0 4d23h 10.244.2.209 node-2 kubia-nt72z 1/1 Running 0 13d 10.244.1.20 node-1 mongodb-nfs 1/1 Running 0 2d17h 10.244.2.212 node-2 [root@master-node Chapter06]# kubectl get nodes -L gpu NAME STATUS ROLES AGE VERSION GPU master-node Ready control-plane,master 79d v1.23.1 node-1 Ready <none> 79d v1.22.3 true node-2 Ready <none> 79d v1.22.3 [root@master-node Chapter06]#
node1 这个worker node上有1个label gpu=true,我们停止当前的pod,并修改其yaml,故意让其运行在node1上:
[root@master-node Chapter06]# kubectl delete pod mongodb-nfs
...
[root@master-node Chapter06]# cat mongodb-pod-nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: mongodb-nfs
spec:
volumes:
- name: mongodb-data
nfs:
server: 172.16.17.7
path: /data/nfs
nodeSelector: #添加nodeSelector,使其运行在特定的node上
gpu: "true"
containers:
- image: mongo
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db
ports:
- containerPort: 27017
protocol: TCP
[root@master-node Chapter06]# 这里,遇到另外一个错误:
[root@master-node Chapter06]# kubectl get pods NAME READY STATUS RESTARTS AGE fortune 2/2 Running 0 7d18h gitrepo-volume-pod 1/1 Running 0 7d18h kubia-4mwx6 1/1 Running 0 14d kubia-htskq 1/1 Running 0 14d kubia-manual 1/1 Running 0 5d kubia-nt72z 1/1 Running 0 14d mongodb-nfs 0/1 CrashLoopBackOff 8 (3m32s ago) 21m [root@master-node Chapter06]# kubectl describe pod mongodb-nfs ... Normal Pulling 18m (x5 over 21m) kubelet Pulling image "mongo" Warning BackOff 63s (x86 over 19m) kubelet Back-off restarting failed container [root@master-node Chapter06]# kubectl logs -f mongodb-nfs WARNING: MongoDB 5.0+ requires a CPU with AVX support, and your current system does not appear to have that! see https://jira.mongodb.org/browse/SERVER-54407 see also https://www.mongodb.com/community/forums/t/mongodb-5-0-cpu-intel-g4650-compatibility/116610/2 see also https://github.com/docker-library/mongo/issues/485#issuecomment-891991814 [root@master-node Chapter06]# #节点1上查看内核日志,也看到类似报错。 [root@node-1 ~]# dmesg -T|tail [一 3月 28 11:07:57 2022] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready [一 3月 28 11:07:57 2022] IPv6: eth0: IPv6 duplicate address fe80::209b:80ff:fe0d:d2bd detected! [一 3月 28 11:09:02 2022] traps: mongod[15689] trap invalid opcode ip:563593c7a51a sp:7fffd91943c0 error:0 in mongod[56358fc89000+5139000] [一 3月 28 11:09:06 2022] traps: mongod[15789] trap invalid opcode ip:55982aa3451a sp:7ffc46e4ed50 error:0 in mongod[559826a43000+5139000] [一 3月 28 11:09:25 2022] traps: mongod[15936] trap invalid opcode ip:558f5dae151a sp:7fffa8e83ba0 error:0 in mongod[558f59af0000+5139000] [一 3月 28 11:09:55 2022] traps: mongod[16114] trap invalid opcode ip:55669ad0551a sp:7fff76c47880 error:0 in mongod[556696d14000+5139000] [一 3月 28 11:10:47 2022] traps: mongod[16375] trap invalid opcode ip:5592de63451a sp:7ffdaa830f60 error:0 in mongod[5592da643000+5139000] [一 3月 28 11:12:17 2022] traps: mongod[16756] trap invalid opcode ip:5586132eb51a sp:7ffd657d8590 error:0 in mongod[55860f2fa000+5139000] [一 3月 28 11:15:11 2022] traps: mongod[17403] trap invalid opcode ip:55e52493951a sp:7ffe2ff6ffe0 error:0 in mongod[55e520948000+5139000] [一 3月 28 11:20:21 2022] traps: mongod[18524] trap invalid opcode ip:555652d3351a sp:7ffed2f01cf0 error:0 in mongod[55564ed42000+5139000] [root@node-1 ~]#
发现,pod想要运行在node1上报错,究其原因是MongoDB 5.0+版本对当前节点node1的CPU支持有限制,上面也有链接提示。我们先不去解决该问题,我们先把MongoDB的image指定为4.0。并重新执行该完整的验证,使其先运行在node2上,然后重启使其运行在node1上。
[root@master-node Chapter06]# kubectl get pods NAME READY STATUS RESTARTS AGE fortune 2/2 Running 0 7d19h gitrepo-volume-pod 1/1 Running 0 7d19h kubia-4mwx6 1/1 Running 0 14d kubia-htskq 1/1 Running 0 14d kubia-manual 1/1 Running 0 5d kubia-nt72z 1/1 Running 0 14d mongodb-nfs 1/1 Running 0 61s [root@master-node Chapter06]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE fortune 2/2 Running 0 7d19h 10.244.2.207 node-2 gitrepo-volume-pod 1/1 Running 0 7d19h 10.244.2.208 node-2 kubia-4mwx6 1/1 Running 0 14d 10.244.2.198 node-2 kubia-htskq 1/1 Running 0 14d 10.244.2.199 node-2 kubia-manual 1/1 Running 0 5d 10.244.2.209 node-2 kubia-nt72z 1/1 Running 0 14d 10.244.1.20 node-1 mongodb-nfs 1/1 Running 0 65s 10.244.1.24 node-1 [root@master-node Chapter06]#
10.6验证pod重新调度之后,数据依然存在
[root@master-node Chapter06]# kubectl exec mongodb-nfs -it -- mongo
MongoDB shell version v4.0.28
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("8389f4b3-026d-4e45-a0ff-ee662b0cd568") }
...
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
mydb 0.000GB
> use mydb
switched to db mydb
> db.collection1.find();
{ "_id" : ObjectId("6242cf68f1f586f3ad24d8e1"), "volumeType" : "NFS" }
> 至此,我们说通过NFS类型的持久化存储,帮我们实现了pod跨node运行时的数据持久化。这也正是Kubernetes中需要volume的原因,解决数据的持久化。
11 PV和PVC
11.1 什么是PV和PVC?
所谓的PV就是persistent volume,是创建于底层存储卷volume上的资源对象;
PVC,persistent volume claim,通过它来使用PV,进而使用底层的持久化存储的;
11.2 PV和PVC的关系?
类似于Java中的接口和实现类的关系。PV是接口,在底层的存储卷上创建出来的资源对象,你想要使用底层的存储卷做数据的持久化,那么你就得通过我来完成,我给底层的存储卷提供了统一的访问接口;而PVC好比如接口的实现类,操作和使用底层的持久化存储卷,具体是通过调用我来实现的。
11.3为什么需要PV和PVC?
我们在前面使用的持久化存储方案中,需要应用开发人员对于底层的存储比较熟悉。比如,使用NFS类型的volume时,我们需要先创建和配置好NFS,然后开发人员在应用的yaml文件中对其配置。如果把这个应用的yaml拿到1个没有配置NFS volume的Kubernetes cluster中,或者一个NFS的配置不同的Kubernetes cluster中,都无法正常运行这个应用了。也就是说,当前的这个yaml文件不具备通用性和可执行性,它和当前的cluster环境耦合的比较紧,这有悖于Kubernetes的设计思想。于是,Kubernetes的开发者抽象了2个存储对象层,在现有的volume上创建1个PV和PVC对象,然后应用程序(pod)的yaml文件里通过pvc和这个PV绑定,进而应用可以正常使用底层持久化存储的方案。其结果就是,应用的yaml文件就和底层的volume解耦了,pod也具有了通用的可移植性。pod的开发人员不再需要了解底层的持久化存储了,只需要关注pod就可以了,把他们从底层的存储方案里解放出来了。
当然,具体实现起来:
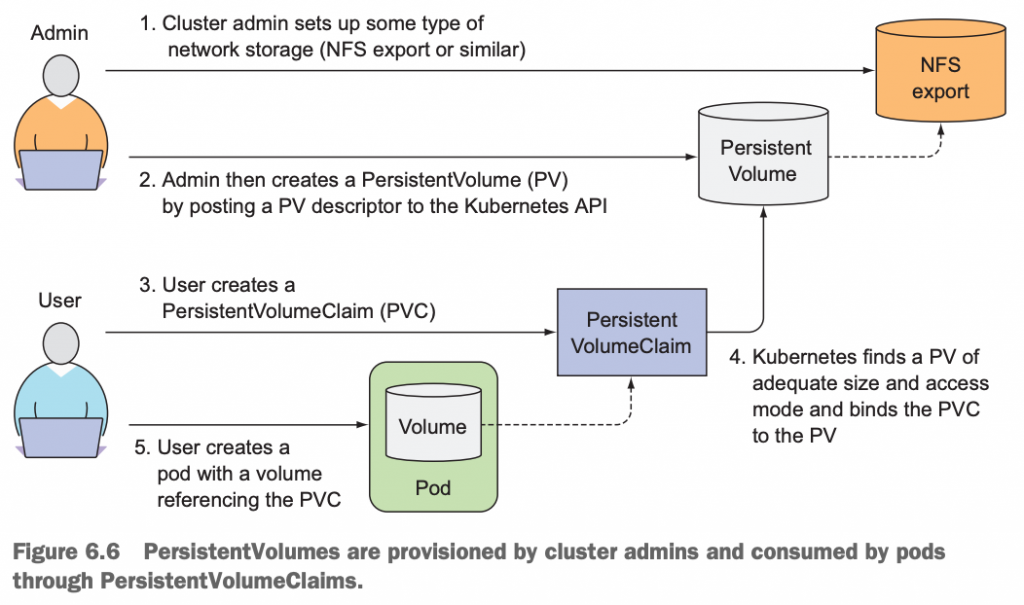
11.4 使用PV和PVC的步骤是什么?
首先,还是需要Kubernetes的管理员来创建和维护底层的存储卷;
然后,在存储卷的基础上创建出PV;
接下来,应用开发人员创建1个PVC,Kubernetes自动将PVC和PV进行了binding;
最后,应用开发人员在pod的yaml里通过使用PVC来创建pod,也就是间接使用PV作为pod的存储。
11.5 使用PV和PVC的案例
我们继续使用这个NFS存储来作为底层的持久化存储卷。需要先停掉前面的pod:mongodb-nfs,并且删除NFS路径上/data/db的文件。
[root@master-node Chapter06]# kubectl delete pod mongodb-nfs [root@master-node Chapter06]#
然后,创建1个PV:它的底层存储是前面挂载的nfs:
[root@master-node Chapter06]# cat mongodb-pv-nfs.yaml
apiVersion: v1
kind: PersistentVolume #资源类型是PV
metadata:
name: mongodb-pv #PV的名字
spec:
capacity:
storage: 1Gi #PV大小
accessModes:
- ReadWriteOnce #只允许1个node可以读写这个PV
- ReadOnlyMany #其它多个node可读这个PV
persistentVolumeReclaimPolicy: Retain #pvc删除之后,其数据依然被保留在PV上
nfs: #指定PV的底层存储,NFS服务器的信息
server: 172.16.17.7
path: /data/nfs
[root@master-node Chapter06]# kubectl apply -f mongodb-pv-nfs.yaml
persistentvolume/mongodb-pv created
[root@master-node Chapter06]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Retain Available 5s
[root@master-node Chapter06]# 接下来,创建PVC,Kubernetes自动帮我们把PVC和PV绑定:
[root@master-node Chapter06]# cat mongodb-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
resources:
requests:
storage: 1Gi
accessModes:
- ReadWriteOnce
storageClassName: ""
[root@master-node Chapter06]# kubectl apply -f mongodb-pvc.yaml
persistentvolumeclaim/mongodb-pvc created
[root@master-node Chapter06]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongodb-pvc Bound mongodb-pv 1Gi RWO,ROX 5s
[root@master-node Chapter06]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Retain Bound default/mongodb-pvc 4m40s
[root@master-node Chapter06]# 很快,我们看到PV的状态从前面的Available,变成现在的bound。同时,也看到PVC的状态如预期那样,和前面创建的PV绑定了。
接下来,创建pod,pod中通过声明使用PVC来使用底层的持久化存储卷:
[root@master-node Chapter06]# cat mongodb-pod-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
containers:
- image: mongo:4.0 #指定MongoDB image version为4.0
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db #挂载到container内的路径
ports:
- containerPort: 27017
protocol: TCP
volumes:
- name: mongodb-data
persistentVolumeClaim:
claimName: mongodb-pvc #声明我要用前面创建出来的PVC
[root@master-node Chapter06]# kubectl apply -f mongodb-pod-pvc.yaml
pod/mongodb created
[root@master-node Chapter06]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
fortune 2/2 Running 0 7d22h 10.244.2.207 node-2 <none> <none>
gitrepo-volume-pod 1/1 Running 0 7d22h 10.244.2.208 node-2 <none> <none>
kubia-4mwx6 1/1 Running 0 14d 10.244.2.198 node-2 <none> <none>
kubia-htskq 1/1 Running 0 14d 10.244.2.199 node-2 <none> <none>
kubia-manual 1/1 Running 0 5d4h 10.244.2.209 node-2 <none> <none>
kubia-nt72z 1/1 Running 0 14d 10.244.1.20 node-1 <none> <none>
mongodb 1/1 Running 0 18s 10.244.2.217 node-2 <none> <none>
[root@master-node Chapter06]#进入MongoDB中查看数据:
[root@master-node Chapter06]# kubectl exec mongodb -it -- /bin/bash
root@mongodb:/# mongo
MongoDB shell version v4.0.28
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("0d63dcae-02fc-45a0-a312-9d9e96f16772") }
MongoDB server version: 4.0.28
Welcome to the MongoDB shell.
....
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
mydb 0.000GB
> use mydb
switched to db mydb
> db.collection1.find();
{ "_id" : ObjectId("6242cf68f1f586f3ad24d8e1"), "volumeType" : "NFS" }
> 这时,看到比较有意思的现象:这条数据,就是之前我们把NFS当持久化方案的pod里写入的数据,当我们通过PV和PVC来使用同一个NFS的时候,发现原来的数据还在。
停掉pod,再重新启动,并有意使其调度到node1上去:
[root@master-node Chapter06]# kubectl delete pod mongodb
pod "mongodb" deleted
[root@master-node Chapter06]# cat mongodb-pod-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: mongodb
spec:
containers:
- image: mongo:4.0
name: mongodb
volumeMounts:
- name: mongodb-data
mountPath: /data/db
ports:
- containerPort: 27017
protocol: TCP
nodeSelector:
gpu: "true"
volumes:
- name: mongodb-data
persistentVolumeClaim:
claimName: mongodb-pvc
[root@master-node Chapter06]# kubectl apply -f mongodb-pod-pvc.yaml
pod/mongodb created
[root@master-node Chapter06]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
fortune 2/2 Running 0 7d23h 10.244.2.207 node-2 <none> <none>
gitrepo-volume-pod 1/1 Running 0 7d23h 10.244.2.208 node-2 <none> <none>
kubia-4mwx6 1/1 Running 0 14d 10.244.2.198 node-2 <none> <none>
kubia-htskq 1/1 Running 0 14d 10.244.2.199 node-2 <none> <none>
kubia-manual 1/1 Running 0 5d4h 10.244.2.209 node-2 <none> <none>
kubia-nt72z 1/1 Running 0 14d 10.244.1.20 node-1 <none> <none>
mongodb 1/1 Running 0 5s 10.244.1.26 node-1 <none> <none>
[root@master-node Chapter06]#发现数据依然存在:
[root@master-node Chapter06]# kubectl exec mongodb -it -- mongo
MongoDB shell version v4.0.28
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("bce26149-750b-4248-a6af-bdda410b4866") }
...
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
mydb 0.000GB
> use mydb
switched to db mydb
> db.collection1.find();
{ "_id" : ObjectId("6242cf68f1f586f3ad24d8e1"), "volumeType" : "NFS" }
> 11.6 PV和PVC的属性关系
PV的容量空间、读写属性必须要满足|覆盖PVC的相应属性。即,如果PVC声明的空间是10GB,而当前的PV大小是1GB,这时该PVC不可能和这个PV绑定。
11.7 PV的capacity|accessModes|volumeMode属性
我们在前面的PV中,分别定义了capacity和accessModes,没有显示的去声明volumeMode,其默认值是filesystem值。
在Kubernetes里,定义PV容量大小的单位写法后缀都是小写字符i,比如想定义100MB的PV,则写100Mi,2TB的PV,则2Ti。
accessModes访问属性针对的是PVC不是pod,分为3种:
- RWO —
ReadWriteOnce—Only a single node can mount the volume for reading and writing. - ROX —
ReadOnlyMany—Multiple nodes can mount the volume for reading. - RWX —
ReadWriteMany—Multiple nodes can mount the volume for both reading and writing.
如上,我们通过kubectl get pv;看到的ACCESS MODES列的结果值。
11.8 PV的Reclaim policy
该策略指的是PVC被删除而不是PV被删除之后,PV里的内容如何保留的策略。
The reclaim policy determines what happens when a persistent volume claim is deleted.分为3种:
Retain:PV里的数据保留,且该PV如果想要被其它PVC使用的话,该PV需要重新创建。
Delete:内容被清理,
Recycle:循环利用。
11.8.1 PV的reclaim policy为retain
如上,我们的PV的保留策略设置的是Retain。意味着,我们删除PVC之后,PV里的数据被retain保留。但是重建该PVC之后,发现它不能再次绑定到该PV上。
删除pod和PVC之后,发现PV的状态变为Released。但是,重建PVC之后,发现PVC的状态是pending,不能和原来的PV绑定。
[root@master-node Chapter06]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE mongodb-pv 1Gi RWO,ROX Retain Bound default/mongodb-pvc 23h [root@master-node Chapter06]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mongodb-pvc Bound mongodb-pv 1Gi RWO,ROX 23h [root@master-node Chapter06]# kubectl get pods NAME READY STATUS RESTARTS AGE fortune 2/2 Running 0 10d gitrepo-volume-pod 1/1 Running 0 9d kubia-4mwx6 1/1 Running 0 16d kubia-htskq 1/1 Running 0 16d kubia-manual 1/1 Running 0 7d5h kubia-nm2fq 1/1 Running 0 28h mongodb 1/1 Running 0 23h [root@master-node Chapter06]# kubectl delete pod mongodb pod "mongodb" deleted [root@master-node Chapter06]# kubectl delete pvc mongodb-pvc persistentvolumeclaim "mongodb-pvc" deleted [root@master-node Chapter06]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE mongodb-pv 1Gi RWO,ROX Retain Released default/mongodb-pvc 23h [root@master-node Chapter06]# kubectl get pvc No resources found in default namespace. [root@master-node Chapter06]# kubectl apply -f mongodb-pvc.yaml persistentvolumeclaim/mongodb-pvc created [root@master-node Chapter06]# kubectl get pv #PV的状态为Released,但是它不能直接被再次使用 NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE mongodb-pv 1Gi RWO,ROX Retain Released default/mongodb-pvc 23h [root@master-node Chapter06]# kubectl get pvc #PVC的状态为pending,不能和PV绑定 NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mongodb-pvc Pending 5m39s [root@master-node Chapter06]#
更进一步,此时,删除pod,PVC和PV之后。再次重建该PV、PVC、pod之后,会发现pod还能读取之前NFSvolume里的数据。验证方式,见下一小节里的实验结论。
11.8.2 测试验证PV的reclaim policy为delete
删除现有的pod,pvc,pv:
[root@master-node Chapter06]# kubectl delete pvc mongodb-pvc persistentvolumeclaim "mongodb-pvc" deleted [root@master-node Chapter06]# kubectl delete pv mongodb-pv persistentvolume "mongodb-pv" deleted [root@master-node Chapter06]# kubectl get pv No resources found [root@master-node Chapter06]# kubectl get pvc No resources found in default namespace. [root@master-node Chapter06]#
创建reclaim policy为delete的PV,以及PVC,和pod:
[root@master-node Chapter06]# cat mongodb-pv-nfs.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongodb-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Delete #策略是Delete
nfs:
server: 172.16.17.7
path: /data/nfs
[root@master-node Chapter06]# kubectl apply -f mongodb-pv-nfs.yaml
persistentvolume/mongodb-pv created
[root@master-node Chapter06]# kubectl get pv #策略是Delete
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Delete Available 5s
[root@master-node Chapter06]# kubectl apply -f mongodb-pvc.yaml
persistentvolumeclaim/mongodb-pvc created
[root@master-node Chapter06]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongodb-pvc Bound mongodb-pv 1Gi RWO,ROX 5s
[root@master-node Chapter06]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Delete Bound default/mongodb-pvc 76s
[root@master-node Chapter06]# kubectl apply -f mongodb-pod-pvc.yaml
pod/mongodb created
[root@master-node Chapter06]# kubectl get pods
NAME READY STATUS RESTARTS AGE
fortune 2/2 Running 0 10d
gitrepo-volume-pod 1/1 Running 0 10d
kubia-4mwx6 1/1 Running 0 16d
kubia-htskq 1/1 Running 0 16d
kubia-manual 1/1 Running 0 7d5h
kubia-nm2fq 1/1 Running 0 29h
mongodb 1/1 Running 0 13s
[root@master-node Chapter06]# kubectl exec mongodb -it -- /bin/bash
root@mongodb:/# mongo
...
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
mydb 0.000GB
> use mydb #此时,依然可以读取前面章节10.8.1,更进一步,此时,删除pod,PVC和PV之后。再次重建该PV、PVC、pod之后,会发现pod还能读取之前NFS volume里的数据。
switched to db mydb
> show tables;
collection1
> db.collection1.find();
{ "_id" : ObjectId("6242cf68f1f586f3ad24d8e1"), "volumeType" : "NFS" }
> exit
bye
root@mongodb:/# 删除pod,PVC之后,
[root@master-node Chapter06]# kubectl delete pod mongodb pod "mongodb" deleted [root@master-node Chapter06]# kubectl delete pvc mongodb-pvc persistentvolumeclaim "mongodb-pvc" deleted [root@master-node Chapter06]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE mongodb-pv 1Gi RWO,ROX Delete Failed default/mongodb-pvc 10m [root@master-node Chapter06]# kubectl get pvc No resources found in default namespace. [root@master-node Chapter06]#
这里,发现PV的状态是Failed:
[root@master-node Chapter06]# kubectl describe pv Name: mongodb-pv Labels: <none> Annotations: pv.kubernetes.io/bound-by-controller: yes Finalizers: [kubernetes.io/pv-protection] ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning VolumeFailedDelete 6m50s persistentvolume-controller error getting deleter volume plugin for volume "mongodb-pv": no deletable volume plugin matched [root@master-node Chapter06]#
查了Kubernetes官网:https://kubernetes.io/docs/concepts/storage/persistent-volumes/#reclaim-policy 原来是AWS EBS, GCE PD, Azure Disk, and Cinder volumes support deletion. NFS不支持delete策略。
11.8.3 测试验证PV的reclaim policy为recycle
删除现有PV,PVC:
[root@master-node Chapter06]# kubectl delete pvc mongodb-pvc persistentvolumeclaim "mongodb-pvc" deleted [root@master-node Chapter06]# kubectl delete pv mongodb-pv persistentvolume "mongodb-pv" deleted [root@master-node Chapter06]# kubectl get pv No resources found [root@master-node Chapter06]# kubectl get pvc No resources found in default namespace. [root@master-node Chapter06]#
创建reclaim policy为recycle的PV,继续创建pvc和pod:
[root@master-node Chapter06]# cat mongodb-pv-nfs.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongodb-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Recycle #策略是Recycle
nfs:
server: 172.16.17.7
path: /data/nfs
[root@master-node Chapter06]# kubectl apply -f mongodb-pv-nfs.yaml
persistentvolume/mongodb-pv created
[root@master-node Chapter06]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Recycle Available 4s
[root@master-node Chapter06]# kubectl apply -f mongodb-pvc.yaml
persistentvolumeclaim/mongodb-pvc created
[root@master-node Chapter06]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongodb-pvc Bound mongodb-pv 1Gi RWO,ROX 5s
[root@master-node Chapter06]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Recycle Bound default/mongodb-pvc 25s
[root@master-node Chapter06]# kubectl apply -f mongodb-pod-pvc.yaml
pod/mongodb created
[root@master-node Chapter06]# kubectl exec mongodb -it -- mongo
...
> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
mydb 0.000GB
> use mydb
switched to db mydb
> db.collection1.find()
{ "_id" : ObjectId("6242cf68f1f586f3ad24d8e1"), "volumeType" : "NFS" }
> exit
bye
[root@master-node Chapter06]#删除pod,PVC,再重建pvc和pod:
[root@master-node Chapter06]# kubectl delete pod mongodb
pod "mongodb" deleted
[root@master-node Chapter06]# kubectl delete pvc mongodb-pvc
persistentvolumeclaim "mongodb-pvc" deleted
[root@master-node Chapter06]# kubectl apply -f mongodb-pvc.yaml #重建PVC
persistentvolumeclaim/mongodb-pvc created
[root@master-node Chapter06]# kubectl get pv #PV状态重新bound
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mongodb-pv 1Gi RWO,ROX Recycle Bound default/mongodb-pvc 4m4s
[root@master-node Chapter06]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mongodb-pvc Bound mongodb-pv 1Gi RWO,ROX 6s
[root@master-node Chapter06]# kubectl apply -f mongodb-pod-pvc.yaml #重建pod
pod/mongodb created
[root@master-node Chapter06]# kubectl exec mongodb -it -- mongo
MongoDB shell version v4.0.28
connecting to: mongodb://127.0.0.1:27017/?gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("b64f4eab-f113-4b3a-844c-bf38ac5ba26e") }
MongoDB server version: 4.0.28
...
> show dbs; #终于,由于PV的reclaim policy=recycle,这次看不到之前的旧数据了。
admin 0.000GB
config 0.000GB
local 0.000GB
> 12 小结
本章学习了为什么我们需要volume;
volume的作用;
volume和pod,container之前的关系;
创建1个包含多个container的pod,通过volume实现container共享数据;
了解emptyDir和hostPath、gitRepo的场景;
通过NFS来实现持久化存储;
PV和PVC的作用以及如何使用;