Kubernetes in Action读书笔记第五章:Service资源对象
本章主要内容
- 我们为什么需要Service资源对象
- Service资源对象是什么
- 如何创建和使用Service
- Service和pod是如何关联的
- 访问Service资源对象的两种方式:内部|外部
- Service资源对象的分类
- Service资源对象的底层实现原理是什么
- Pod的readiness Probe
- Service故障诊断tips
Contents
- 1 我们为什么需要Service资源对象?
- 2 Service资源对象是什么
- 3 Service和pod是如何关联的?
- 4 Service资源对象的两种访问方式
- 5 创建Service资源对象的两种方式
- 6 Service资源对象的分类
- 7如何创建并验证ClusterIP类型的Service资源对象
- 8 如何创建并验证NodePort类型的Service资源对象
- 9 如何创建并验证Loadbalancer类型的Service资源对象
- 10 如何创建并验证Ingress类型的Service资源对象
- 11 Service的底层实现原理是什么?
- 12 Service discovery是怎么实现的?
- 13 Service的sessionAffinity
- 14 Service的externalTrafficPolicy属性
- 15 Pod的readiness probe
- 16 Service故障诊断tips
- 17 本地Kubernetes cluster安装配置使用ingress
- 18小结
1 我们为什么需要Service资源对象?
想要解释清楚这个问题。首先,我们先回顾一下,当前在我们的Kubernetes cluster中,我们部署了诸多应用,它们最终是运行在Pod中的container中的。如果我们想要访问这些container提供的服务的话,我们该怎么办呢?可以通过container或者Pod的IP来访问吗?不能。因为:
Pod的生命周期是短暂的,有可能被重新调度,被重启;
Pod一旦被重启,它的IP地址将发生变化,显然通过它的IP来访问它提供的服务是不太现实的;
Pod有可能被水平扩展(向上变多,向下变少),那么究竟该选择哪个具体的Pod来访问服务呢?
如果选定某个Pod来访问服务的话,一旦这个Pod出现故障怎么办?单点故障避免不了;
水平扩展多个Pod来提供服务的负载均衡,访问某个特定的pod话,就没法实现负载均衡了。
因此,基于上述种种原因,我们不应该通过直接访问pod来访问它提供的服务。于是,人们在Pod的基础上封装出了一个资源对象,称之为Service。它可以解决上述种种问题。具体是怎么解决的呢?我们继续。
2 Service资源对象是什么
Service是我们在Kubernetes里创建的1个资源对象,用于封装1个或1组pod(把它们绑定在一起),Service自身拥有1个静态的IP地址和端口,我们通过访问Service来间接的访问它底层的Pod提供的服务。
A Kubernetes Service is a resource you create to make a single, constant point of entry to a group of pods providing the same service. Each service has an IP address and port that never change while the service exists. Clients can open connections to that IP and port, and those connections are then routed to one of the pods backing that service. This way, clients of a service don’t need to know the location of individual pods providing the service, allowing those pods to be moved around the cluster at any time.
P153
2.1 Service的一个典型应用场景举例
假定1个前端服务,由多个pod组成,1个后端的数据库给前端工程提供服务。此时,我们可以把前端的3个Pod封装在一起,抽象出1个Service对象出来,把它的IP地址和端口,开放给客户端访问,而不是让客户端直接找到我这3个pod。同时,后端的数据库也可以封装成1个服务,把它的IP和端口,开放给前端的那3个Pod去访问,而不是让pod直接来访问数据库的这个后端pod。
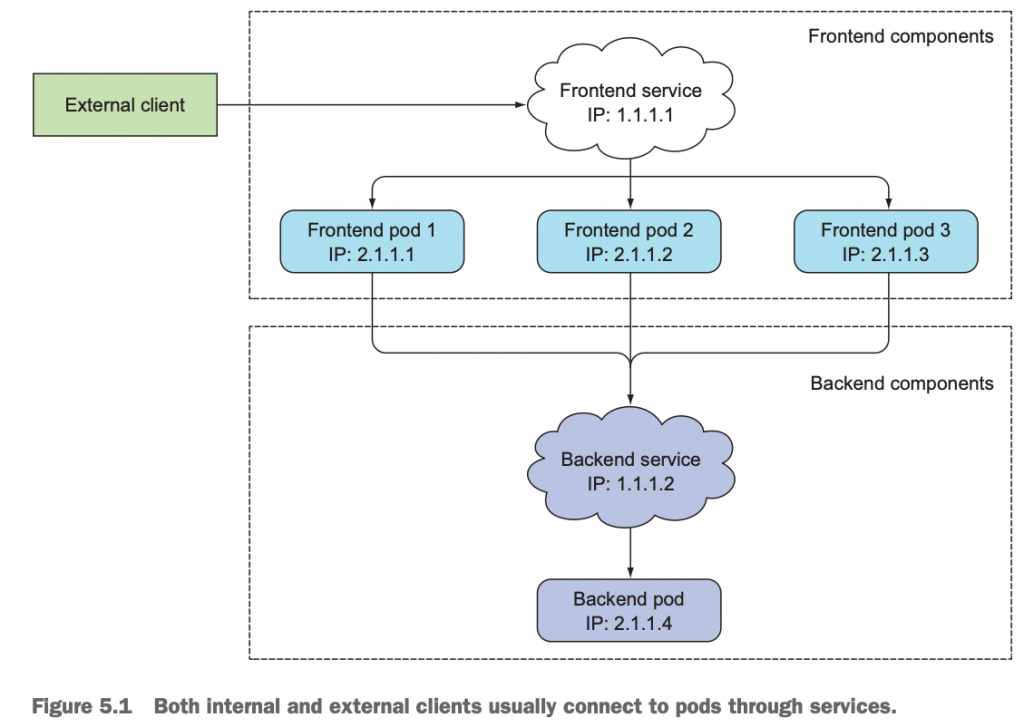
3 Service和pod是如何关联的?
既然Service是基于一个或一组pod封装出来的资源对象,且可以通过访问Service对象来间接的访问它底层的pods提供的服务的。那么它是怎么实现的呢?
答案是label selector。即Pod上有label,Service上有pod的label selector。这样就把它们关联在一起了,如同前面我们知道的ReplicationController、ReplicaSet、DaemonSet和Job以及CronJob都是通过pod selector和pod产生关联,一样的道理。
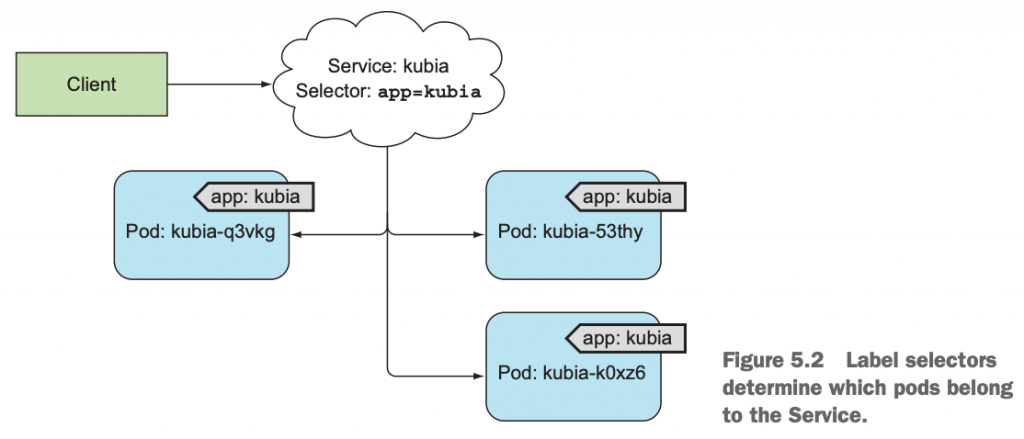
4 Service资源对象的两种访问方式
显然,pod提供的服务就可以给cluster中的其它pod访问,也可以提供给cluster外的应用访问。因此,可以把访问服务分为两类:内部访问,外部访问。
很显然,服务是有cluster中的pod提供的,那么想要访问它就可以分为两种方式:在cluster内部访问,cluster外部访问。
5 创建Service资源对象的两种方式
我们在前面的第二章 3.3章节学习了通过命令kubectl expose pod把pod以Service的形式暴露出去,也可以通过yaml文件来创建1个Service资源对象。我们通常采用yaml文件的方式来创建Service资源对象。
6 Service资源对象的分类
- ClusterIP:默认类型的Service资源对象;只能在Kubernetes cluster内部通过cluster IP+端口来访问服务;
- NodePort: ClusterIP类型的Service对象的超集,除了可以在Kubernetes cluster 内部通过Cluster IP+端口访问访问之外,还可以通过整个集群中的每个node的IP+端口来访问服务;
- Loadbalancer:它是NodePort 类型Service资源对象的超集,除了可以通过整个集群中的每个node的IP+端口来访问服务之外,还可以通过一个公网IP地址来访问服务;
- Ingress:它是Loadbalancer的超集,1个Loadbalancer只能对应1个Service资源对象;而1个Ingress可以对应多个不同的服务;
7如何创建并验证ClusterIP类型的Service资源对象
7.1先创建ReplicaSet,通过ReplicaSet间接创建pod出来
创建前,default namespace下,没有pod,也没有ReplicaSet,只有1个Kubernetes Cluster系统默认的Service,名为kubernetes,我们先不管它:
[root@master-node Chapter04]# kubectl get pods No resources found in default namespace. [root@master-node Chapter04]# kubectl get rs No resources found in default namespace. [root@master-node Chapter04]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14d [root@master-node Chapter04]#
使用第四章的kubia-replicaset.yaml 来创建ReplicaSet和pods:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat kubia-replicaset.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
[root@master-node Chapter04]# kubectl apply -f kubia-replicaset.yaml
replicaset.apps/kubia created
[root@master-node Chapter04]# kubectl get pods -owide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
kubia-4mwx6 1/1 Running 0 33s 10.244.2.198 node-2 <none> <none> app=kubia
kubia-htskq 1/1 Running 0 33s 10.244.2.199 node-2 <none> <none> app=kubia
kubia-nt72z 1/1 Running 0 33s 10.244.1.20 node-1 <none> <none> app=kubia
[root@master-node Chapter04]# kubectl get replicasets.apps
NAME DESIRED CURRENT READY AGE
kubia 3 3 3 42s
[root@master-node Chapter04]# 7.2 创建Service资源对象
[root@master-node Chapter05]# pwd
/root/kubernetes-in-action/Chapter05
[root@master-node Chapter05]# cat kubia-svc.yaml
apiVersion: v1
kind: Service #类型为Service资源对象
metadata:
name: kubia #Service名为kubia
spec:
ports:
- port: 80 #Service对外提供的端口是80
targetPort: 8080 #Pod端口是8080
selector:
app: kubia
[root@master-node Chapter05]# kubectl apply -f kubia-svc.yaml
service/kubia created
[root@master-node Chapter05]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14d
kubia ClusterIP 10.101.149.183 <none> 80/TCP 21s
[root@master-node Chapter05]# 7.3验证ClusterIP类型的Service资源对象
在当前Kubernetes Cluster内部,所有的节点上,都可以通过Service资源对象的Cluster IP+端口访问:
[root@master-node Chapter05]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14d kubia ClusterIP 10.101.149.183 <none> 80/TCP 21s [root@master-node Chapter05]# curl 10.101.149.183 You've hit kubia-nt72z [root@master-node Chapter05]# curl 10.101.149.183 You've hit kubia-nt72z [root@master-node Chapter05]# curl 10.101.149.183 You've hit kubia-4mwx6 [root@master-node Chapter05]# curl 10.101.149.183 You've hit kubia-4mwx6 [root@master-node Chapter05]# curl 10.101.149.183 You've hit kubia-htskq [root@master-node Chapter05]#
我们的Service对象名为kubia,它的Cluster-IP为10.101.149.183,访问端口是80。我们可以在当前Cluster的任意节点上通过该IP+端口访问。我们有可以看到curl 10.101.149.183每次访问返回的主机名不固定,因为该Service下其实是有ReplicaSet下的3个不同的pod提供的服务。
那么,离开当前的Kubernetes Cluster能不能访问该服务呢?
不能。这就是默认的Cluster IP类型的Service资源对象的限制特征,只能在当前Kubernetes Cluster内部访问。
8 如何创建并验证NodePort类型的Service资源对象
8.1 创建NodePort类型的Service资源对象
[root@master-node Chapter05]# cat kubia-svc-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort
ports:
- port: 80 #Service访问端口,80
targetPort: 8080 #底层Pod端口:8080
nodePort: 30123 #NodePort端口,即任意节点都通过该端口来访问服务,该参数可以不在这里指定,由Kubernetes帮我们选定一个端口
selector:
app: kubia
[root@master-node Chapter05]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14d
kubia ClusterIP 10.101.149.183 <none> 80/TCP 167m
[root@master-node Chapter05]# kubectl apply -f kubia-svc-nodeport.yaml
service/kubia-nodeport created
[root@master-node Chapter05]# 我们仅仅创建了1个NodePort的Service资源对象,底层的Pod还是采用前面的示例的名为kubia的ReplicaSet管控的3个pod。
8.2验证NodePort Service资源对象
[root@master-node Chapter05]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14d kubia ClusterIP 10.101.149.183 <none> 80/TCP 167m kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 7s [root@master-node Chapter05]# curl 10.110.90.145 You've hit kubia-htskq [root@master-node Chapter05]# curl 10.110.90.145:80 You've hit kubia-4mwx6 [root@master-node Chapter05]# curl 172.16.11.168:30123 You've hit kubia-4mwx6 [root@master-node Chapter05]# curl 172.16.11.148:30123 You've hit kubia-4mwx6 [root@master-node Chapter05]# curl 172.16.11.161:30123 You've hit kubia-nt72z [root@master-node Chapter05]#
我们看到名为kubia-nordport的Service对象,它的Cluter IP是10.110.90.145,访问端口在80。同时,它的类型是NodePort,那么可以通过cluster中任意节点的IP加端口30123来访问服务。
接下来,我们可以通过cluster外的其它客户端来访问该NodePort类型的服务:
通过我的Mac客户端来访问:
$ curl 172.16.11.161:30123 You've hit kubia-nt72z asher at MacBook-Air-3 in ~ $
这,验证了NodePort Service除了可以通过Node IP+端口访问服务,还可以通过Cluster IP+端口访问。因为它是Cluster IP的超集。
8.3 NodePort访问架构图
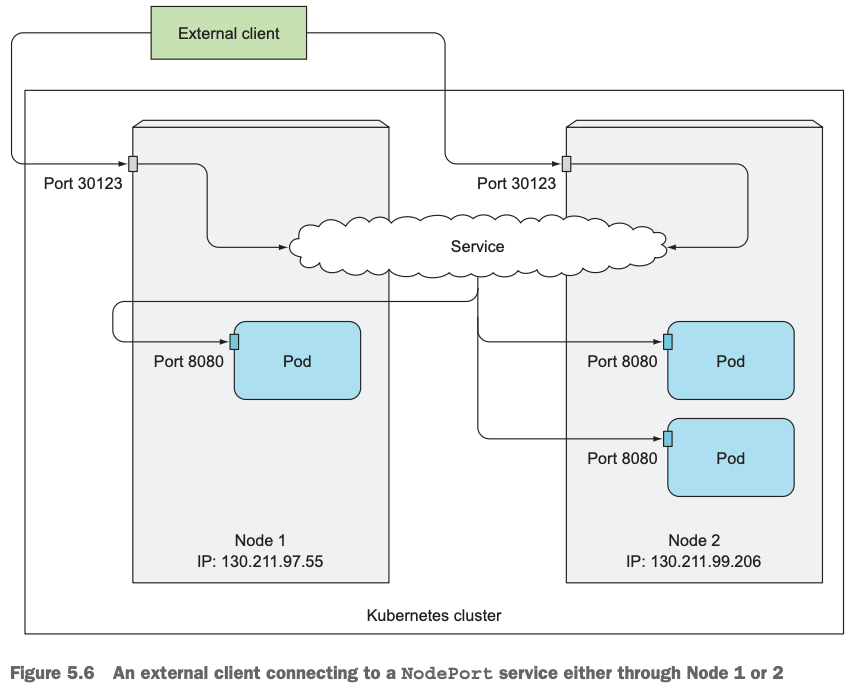
客户端通过NodePort类型服务的IP+端口30123访问服务,请求到每个node的30123端口,然后再把服务请求转发到运行在各个node上的pod的8080端口上去。
9 如何创建并验证Loadbalancer类型的Service资源对象
9.1创建Loadbalancer类型的Service资源对象
如果是通过本地部署的Kubernetes cluster,或者采用的minikube环境是无法验证该类型的Service资源对象。因为,它需要一个公网IP。而云服务商,(Google的GCE或者亚马逊、微软都有提供,Oracle 的Oracle Kubernetes Engine也有提供)。我这里,以我的Oracle Cloud环境来演示。
user@cloudshell:~ (ap-osaka-1)$ kubectl apply -f nginx_lb.yaml deployment.apps/my-nginx created service/my-nginx-svc created user@cloudshell:~ (ap-osaka-1)$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10h my-nginx-svc LoadBalancer 10.96.252.106 <pending> 80:32064/TCP 9s user@cloudshell:~ (ap-osaka-1)$
过一会儿或者,Oracle Kubernetes Engine帮我创建了LoadBalancer:
user@cloudshell:~ (ap-osaka-1)$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10h my-nginx-svc LoadBalancer 10.96.252.106 168.138.55.28 80:32064/TCP 2m48s user@cloudshell:~ (ap-osaka-1)$ kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES my-nginx-5d59d67564-8lwh7 1/1 Running 0 3m21s 10.244.0.7 10.0.10.9 <none> <none> user@cloudshell:~ (ap-osaka-1)$
其中 nginx_lb.yaml文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: renguzi/oke #换成了我自己的image,修改NGINX的index.html,已经推送至DockerHub
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer #Service类型为Loadbalancer
ports:
- port: 80
selector:
app: nginx9.2 验证Loadbalancer Service资源对象
通过Loadbalancer公网IP+端口(这里是80)。
通过互联网直接访问服务:http://168.138.55.28/
9.3访问Loadbalancer服务架构图
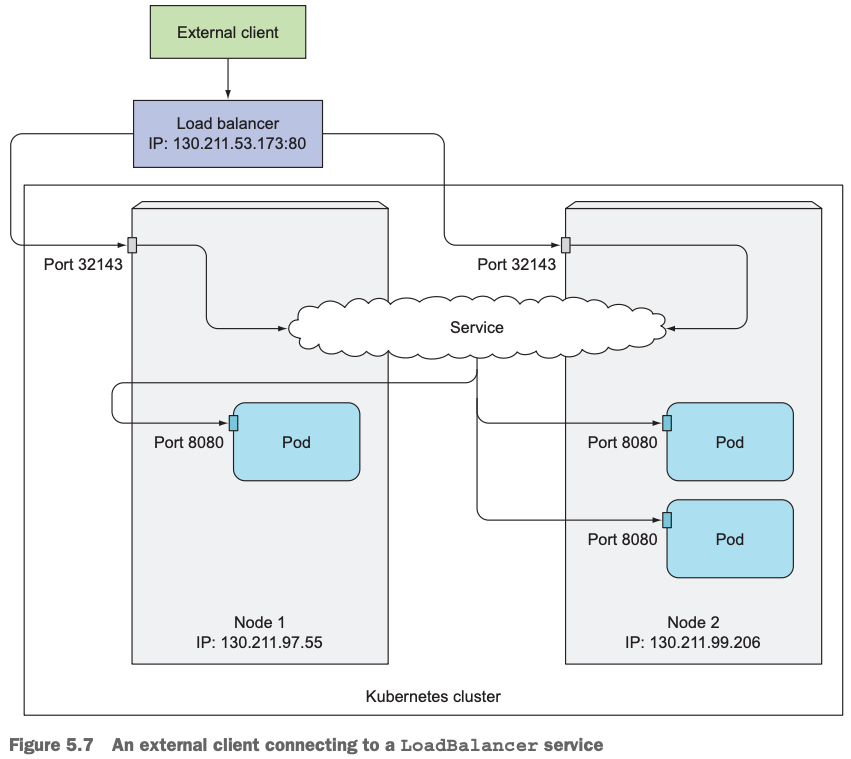
客户端通过Loadbalancer IP+端口访问服务,Loadbalancer先把收到的请求路由到后端的Node上,然后再到各个Node上的pod上。可以看到,Loadbalancer是NodePort的超集,服务请求到了Node之后,服务请求走的流程跟NodePort一样。
10 如何创建并验证Ingress类型的Service资源对象
10.1为什么需要Ingress服务
因为对于Loadbalancer而言,每一个后端的Service资源对象,都需要1个独立的Loadbalancer与之相对应。那么有没有后端有多个服务,前端可以通过一个公网IP+不同的路径来区分后端不同的服务呢?
有,那就是Ingress类型的Service资源对象。
One important reason is that each LoadBalancer service requires its own load balancer with its own public IP address, whereas an Ingress only requires one, even when providing access to dozens of services. When a client sends an HTTP request to the Ingress, the host and path in the request determine which service the request is forwarded to, as shown in figure 5.9.
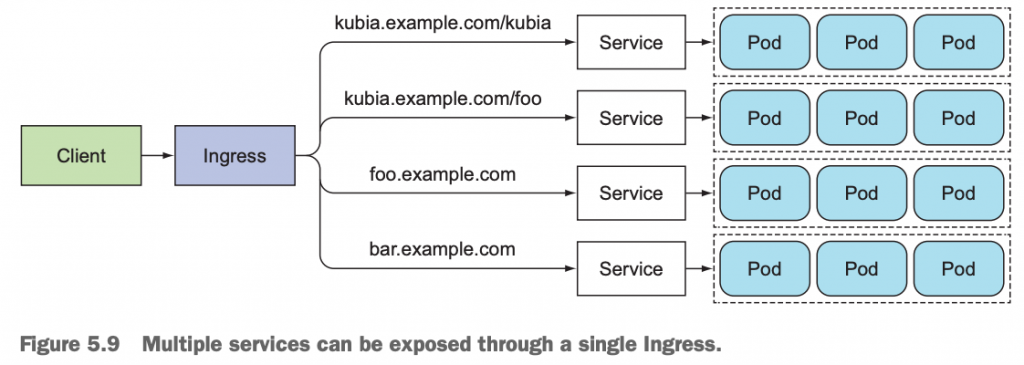
10.2 创建部署ingress Service资源对象
参考:https://docs.oracle.com/en-us/iaas/Content/ContEng/Tasks/contengsettingupingresscontroller.htm
同样,在Oracle cloud kubernetes环境上,执行:
# 1 创建初始化配置信息:包含namespace,角色,权限,ingress controller等,该配置文件地址:https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.44.0/deploy/static/provider/cloud/deploy.yaml
user@cloudshell:~ (ap-osaka-1)$ kubectl apply -f deploy.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
configmap/ingress-nginx-controller created
clusterrole.rbac.authorization.k8s.io/ingress-nginx unchanged
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx unchanged
role.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
service/ingress-nginx-controller-admission created
service/ingress-nginx-controller created
deployment.apps/ingress-nginx-controller created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission configured
serviceaccount/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission unchanged
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission unchanged
role.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
user@cloudshell:~ (ap-osaka-1)$
# 2 创建loadbalancer类型的Service:
user@cloudshell:~ (ap-osaka-1)$ cat cloud-generic.yaml
kind: Service
apiVersion: v1
metadata:
name: ingress-nginx
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
type: LoadBalancer
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
ports:
- name: http
port: 80
targetPort: http
- name: https
port: 443
targetPort: https
user@cloudshell:~ (ap-osaka-1)$ kubectl apply -f cloud-generic.yaml
service/ingress-nginx created
user@cloudshell:~ (ap-osaka-1)$
#### 3 拿到ingress-nginx的公网IP: 152.69.205.99
user@cloudshell:~ (ap-osaka-1)$ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx LoadBalancer 10.96.101.118 152.69.205.99 80:32489/TCP,443:32700/TCP 58s
ingress-nginx-controller LoadBalancer 10.96.3.197 152.69.203.208 80:32481/TCP,443:32581/TCP 105s
ingress-nginx-controller-admission ClusterIP 10.96.158.245 <none> 443/TCP 105s
user@cloudshell:~ (ap-osaka-1)$
#### 4 #创建加密的TLS(Transport Layer Security) 的secret
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc"
user@cloudshell:~ (ap-osaka-1)$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc"
Generating a 2048 bit RSA private key
************************************************************************************************************************************************************************************************************************************+++++
writing new private key to 'tls.key'
-----
user@cloudshell:~ (ap-osaka-1)$
###### 5 创建secret
kubectl create secret tls tls-secret --key tls.key --cert tls.crt
###### 6 创建后端应用的Service
user@cloudshell:~ (ap-osaka-1)$ cat hello-world-ingress.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: docker-hello-world
labels:
app: docker-hello-world
spec:
selector:
matchLabels:
app: docker-hello-world
replicas: 3
template:
metadata:
labels:
app: docker-hello-world
spec:
containers:
- name: docker-hello-world
image: scottsbaldwin/docker-hello-world:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: docker-hello-world-svc
spec:
selector:
app: docker-hello-world
ports:
- port: 8088
targetPort: 80
type: ClusterIP
user@cloudshell:~ (ap-osaka-1)$ kubectl create -f hello-world-ingress.yaml
deployment.apps/docker-hello-world created
service/docker-hello-world-svc created
user@cloudshell:~ (ap-osaka-1)$
#### 7 创建ingress资源
user@cloudshell:~ (ap-osaka-1)$ cat ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: hello-world-ing
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
tls:
- secretName: tls-secret
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: docker-hello-world-svc
port:
number: 8088
user@cloudshell:~ (ap-osaka-1)$
#### 8 访问服务:
user@cloudshell:~ (ap-osaka-1)$ kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default docker-hello-world-svc ClusterIP 10.96.171.156 <none> 8088/TCP 71m
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d17h
default my-nginx-svc LoadBalancer 10.96.16.101 168.138.55.28 80:32751/TCP 3d5h
ingress-nginx ingress-nginx LoadBalancer 10.96.101.118 152.69.205.99 80:32489/TCP,443:32700/TCP 73m
ingress-nginx ingress-nginx-controller LoadBalancer 10.96.3.197 152.69.203.208 80:32481/TCP,443:32581/TCP 74m
ingress-nginx ingress-nginx-controller-admission ClusterIP 10.96.158.245 <none> 443/TCP 74m
kube-system kube-dns ClusterIP 10.96.5.5 <none> 53/UDP,53/TCP,9153/TCP 3d17h
user@cloudshell:~ (ap-osaka-1)$
user@cloudshell:~ (ap-osaka-1)$ kubectl get ingress --all-namespaces
NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE
default hello-world-ing <none> * 152.69.203.208 80, 443 123m
user@cloudshell:~ (ap-osaka-1)$ 在本地通过ingress-nginx-controller的公网IP可以访问服务,http://152.69.203.208/
$ curl http://152.69.203.208/ <h1>Hello webhook world from: docker-hello-world-5cf675d97d-2nr6q</h1> asher at MacBook-Air-3 in ~/.ssh $ curl -I http://152.69.203.208/ HTTP/1.1 200 OK Date: Fri, 18 Mar 2022 08:49:42 GMT Content-Type: text/html Content-Length: 71 Connection: keep-alive Last-Modified: Fri, 18 Mar 2022 07:35:50 GMT ETag: "62343656-47" Accept-Ranges: bytes asher at MacBook-Air-3 in ~/.ssh $
但是通过ingress-nginx的公网IP却不行:
$ curl http://152.69.205.99/ curl: (56) Recv failure: Connection reset by peer asher at MacBook-Air-3 in ~/.ssh $ curl -I http://152.69.205.99/ curl: (56) Recv failure: Connection reset by peer asher at MacBook-Air-3 in ~/.ssh
通过HTTPS协议访问ingres-nginx-controller 的公网IP https://152.69.203.208/
$ curl -k https://152.69.203.208/ <h1>Hello webhook world from: docker-hello-world-5cf675d97d-l8rbz</h1> asher at MacBook-Air-3 in ~/.ssh $ curl -k https://152.69.203.208/ <h1>Hello webhook world from: docker-hello-world-5cf675d97d-g2btw</h1> asher at MacBook-Air-3 in ~/.ssh $ curl -k https://152.69.203.208/ <h1>Hello webhook world from: docker-hello-world-5cf675d97d-2nr6q</h1> asher at MacBook-Air-3 in ~/.ssh $
每次返回的地址都不同,说明负载均衡到后端的不同pods上了:
user@cloudshell:~ (ap-osaka-1)$ kubectl get pods NAME READY STATUS RESTARTS AGE docker-hello-world-5cf675d97d-2nr6q 1/1 Running 0 77m docker-hello-world-5cf675d97d-g2btw 1/1 Running 0 77m docker-hello-world-5cf675d97d-l8rbz 1/1 Running 0 77m my-nginx-7746788f68-crcfq 1/1 Running 0 3d4h my-nginx-7746788f68-gz87k 1/1 Running 0 3d4h my-nginx-7746788f68-rx8hg 1/1 Running 0 3d4h user@cloudshell:~ (ap-osaka-1)$
10.3 killercoda演示ingress类型的Service
10.3.1 实验场景要求和步骤:
Kubernetes cluster中已经安装配置NGINX ingress Controller,有了该Controller才可以创建类型为ingress的Service资源对象;
Kubernetes cluster中已经配置好不同的Service资源对象,指向底层不同的Deployment管控的不同的pod;
最后创建ingress资源对象,通过不同的上下文prefix,指向不同的Service资源对象。这样,通过访问ingress的不同上下文,把服务请求分发到底层不同的Service资源对象上。从而实现通过一个ingress类型的Service可以访问到多个不同的Service。
10.3.2 该环境下,已经安装配置NGINX ingress Controller:
controlplane $ kubectl get ns NAME STATUS AGE default Active 28d ingress-nginx Active 47m kube-node-lease Active 28d kube-public Active 28d kube-system Active 28d world Active 47m controlplane $ kubectl -n ingress-nginx get all NAME READY STATUS RESTARTS AGE pod/ingress-nginx-admission-create-9gtdp 0/1 Completed 0 47m pod/ingress-nginx-admission-patch-jj22g 0/1 Completed 0 47m pod/ingress-nginx-controller-7df574b57c-skncq 1/1 Running 0 47m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/ingress-nginx-controller NodePort 10.111.219.156 <none> 80:30080/TCP,443:30443/TCP 47m service/ingress-nginx-controller-admission ClusterIP 10.103.86.21 <none> 443/TCP 47m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/ingress-nginx-controller 1/1 1 1 47m NAME DESIRED CURRENT READY AGE replicaset.apps/ingress-nginx-controller-7df574b57c 1 1 1 47m NAME COMPLETIONS DURATION AGE job.batch/ingress-nginx-admission-create 1/1 14s 47m job.batch/ingress-nginx-admission-patch 1/1 14s 47m controlplane $
10.3.3 当前world namespace的资源信息如下:
controlplane $ kubectl -n world get all NAME READY STATUS RESTARTS AGE pod/asia-6b67487686-mdzvb 1/1 Running 0 20m pod/asia-6b67487686-vkp7s 1/1 Running 0 20m pod/europe-6676bc64c8-cmstv 1/1 Running 0 20m pod/europe-6676bc64c8-zzjs4 1/1 Running 0 20m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/asia 2/2 2 2 20m deployment.apps/europe 2/2 2 2 20m NAME DESIRED CURRENT READY AGE replicaset.apps/asia-6b67487686 2 2 2 20m replicaset.apps/europe-6676bc64c8 2 2 2 20m controlplane $ kubectl -n world get all -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/asia-6b67487686-mdzvb 1/1 Running 0 20m 192.168.0.8 controlplane <none> <none> pod/asia-6b67487686-vkp7s 1/1 Running 0 20m 192.168.0.6 controlplane <none> <none> pod/europe-6676bc64c8-cmstv 1/1 Running 0 20m 192.168.0.5 controlplane <none> <none> pod/europe-6676bc64c8-zzjs4 1/1 Running 0 20m 192.168.0.7 controlplane <none> <none> NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR deployment.apps/asia 2/2 2 2 20m c nginx:1.21.5-alpine app=asia deployment.apps/europe 2/2 2 2 20m c nginx:1.21.5-alpine app=europe NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR replicaset.apps/asia-6b67487686 2 2 2 20m c nginx:1.21.5-alpine app=asia,pod-template-hash=6b67487686 replicaset.apps/europe-6676bc64c8 2 2 2 20m c nginx:1.21.5-alpine app=europe,pod-template-hash=6676bc64c8 controlplane $
10.3.4 创建类型为cluster IP的Service资源对象:
controlplane $ cat asia-servcie.yaml
apiVersion: v1
kind: Service #类型为Service资源对象
metadata:
name: asia #Service名为asia
spec:
ports:
- port: 80 #Service对外提供的端口是80
targetPort: 80 #Pod端口是80
selector:
app: asia
controlplane $
controlplane $ cat europe-servcie.yaml
apiVersion: v1
kind: Service #类型为Service资源对象
metadata:
name: europe #Service名为europe
spec:
ports:
- port: 80 #Service对外提供的端口是80
targetPort: 80 #Pod端口是80
selector:
app: europe
controlplane $
controlplane $ kubectl -n world apply -f asia-servcie.yaml
service/asia created
controlplane $ kubectl -n world apply -f europe-servcie.yaml
service/europe created
controlplane $ 10.3.5 验证Service资源对象:
controlplane $ kubectl -n world get all NAME READY STATUS RESTARTS AGE pod/asia-6b67487686-mdzvb 1/1 Running 0 22m pod/asia-6b67487686-vkp7s 1/1 Running 0 22m pod/europe-6676bc64c8-cmstv 1/1 Running 0 22m pod/europe-6676bc64c8-zzjs4 1/1 Running 0 22m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/asia ClusterIP 10.101.25.128 <none> 80/TCP 46s service/europe ClusterIP 10.107.123.252 <none> 80/TCP 42s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/asia 2/2 2 2 22m deployment.apps/europe 2/2 2 2 22m NAME DESIRED CURRENT READY AGE replicaset.apps/asia-6b67487686 2 2 2 22m replicaset.apps/europe-6676bc64c8 2 2 2 22m controlplane $ curl 10.101.25.128 hello, you reached ASIA controlplane $ curl 10.107.123.252 hello, you reached EUROPE controlplane $
10.3.6 创建ingress资源对象
controlplane $ cat world-service-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: world
namespace: world
spec:
ingressClassName: nginx
rules:
- host: "world.universe.mine"
http:
paths:
- path: /europe
pathType: Prefix
backend:
service:
name: europe
port:
number: 80
- path: /asia
pathType: Prefix
backend:
service:
name: asia
port:
number: 80
controlplane $
controlplane $ kubectl apply -f world-service-ingress.yaml
ingress.networking.k8s.io/world created
controlplane $ kubectl -n world get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
world nginx world.universe.mine 80 28s
controlplane $ 10.3.7 通过ingress访问验证
controlplane $ kubectl -n world get ingress NAME CLASS HOSTS ADDRESS PORTS AGE world nginx world.universe.mine 80 28s controlplane $ curl http://world.universe.mine:30080/europe/ hello, you reached EUROPE controlplane $ curl http://world.universe.mine:30080/asia/ hello, you reached ASIA controlplane $
从上,我们看到通过ingress一个入口地址,可以访问到底层的不同Service资源对象上。
11 Service的底层实现原理是什么?
表面上看,我们说底层的pod上有label,然后Service通过label selector把它自己和底层的pod关联在了一起。然后通过访问Service的IP+端口就可以了。
11.1 那么Service和pod是直接关联在一起的吗?
其实不是。在它们二者中间还有一个抽象层endpoint。那么什么是endpoint呢?如何查看呢?
11.2 如何查看endpoints的信息?
我们可以通过kubectl describe svc service_name时,就可以看到endpoint信息,如下:
[root@master-node Chapter05]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21d kubia ClusterIP 10.101.149.183 <none> 80/TCP 7d3h kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 7d1h [root@master-node Chapter05]# kubectl describe svc kubia-nodeport Name: kubia-nodeport Namespace: default Labels: <none> Annotations: <none> Selector: app=kubia Type: NodePort IP Family Policy: SingleStack IP Families: IPv4 IP: 10.110.90.145 IPs: 10.110.90.145 Port: <unset> 80/TCP TargetPort: 8080/TCP NodePort: <unset> 30123/TCP Endpoints: 10.244.1.20:8080,10.244.2.198:8080,10.244.2.199:8080 #这就是endpoints信息 Session Affinity: None External Traffic Policy: Cluster Events: <none> [root@master-node Chapter05]#
我们也可以直接查看endpoints的信息:
[root@master-node Chapter05]# kubectl get endpoints NAME ENDPOINTS AGE kubernetes 172.16.11.168:6443 21d kubia 10.244.1.20:8080,10.244.2.198:8080,10.244.2.199:8080 7d4h kubia-nodeport 10.244.1.20:8080,10.244.2.198:8080,10.244.2.199:8080 7d1h [root@master-node Chapter05]# kubectl get endpoints kubia-nodeport NAME ENDPOINTS AGE kubia-nodeport 10.244.1.20:8080,10.244.2.198:8080,10.244.2.199:8080 7d1h [root@master-node Chapter05]#
从上,我们看到两个不同的Service对象(kubia和kubia-nodeport)它们的endpoints其实是一样的,都指向了相同的pod ip+port。
11.3 endpoints的作用是什么?
当客户端请求找到Service的IP和端口时,并不是直接到底层的pod,而是先到endpoints,然后Service Proxy从endpoints中选择1个IP+port对儿,并把请求交给它。我们也可以看到endpoints里的信息,其实也就是对应的Service包含的后端pod的IP和端口。
[root@master-node Chapter05]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-4mwx6 1/1 Running 0 7d4h 10.244.2.198 node-2 <none> <none> kubia-htskq 1/1 Running 0 7d4h 10.244.2.199 node-2 <none> <none> kubia-nt72z 1/1 Running 0 7d4h 10.244.1.20 node-1 <none> <none> [root@master-node Chapter05]#
从另外一个方面,可以说即使Service是通过label selector和Pod发生关联的。但是,endpoints的引入,解耦了Service和Pod的关联。为啥?比如,cluster内部的应用如果想要访问外部的应用提供的服务,那么这时候在cluster内部创建的Service资源对象,是无法通过label selector和pod绑定的,再说了,外部的应用提供的服务,也不一定是通过pod提供的呀,有可能是一个普通的应用。
如果我们单独创建1个Service对象,没有label selector,则Kubernetes不会帮我们创建对应的endpoints对象。接下来,我们可以手工再去创建endpoints资源对象。此时,手工创建的endpoints资源名称必须要与前面创建的Service资源对象同名。否则,endpoints倒是可以创建成功,但是Service没有对应的endpoints,此时的Service是没有意义的
11.4 如何创建1个没有label selector的Service资源对象?
[root@master-node Chapter05]# cat my-external-service-without-label-selector.yaml apiVersion: v1 kind: Service metadata: name: my-external-service spec: ports: - port: 80 [root@master-node Chapter05]# kubectl apply -f my-external-service-without-label-selector.yaml service/my-external-service created [root@master-node Chapter05]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21d kubia ClusterIP 10.101.149.183 <none> 80/TCP 7d5h kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 7d2h my-external-service ClusterIP 10.96.179.130 <none> 80/TCP 7s [root@master-node Chapter05]# kubectl describe svc my-external-service Name: my-external-service Namespace: default Labels: <none> Annotations: <none> Selector: <none> Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.96.179.130 IPs: 10.96.179.130 Port: <unset> 80/TCP TargetPort: 80/TCP Endpoints: <none> Session Affinity: None Events: <none> [root@master-node Chapter05]#
如上,创建了1个名为my-external-service的Service资源对象,其并没有任何label selector,同时,也没有对应的endpoints信息,默认情况下,Service资源对象是ClusterIP类型的。
11.5 如何手工创建endpoints资源对象?
在创建之前,我们现在其它机器上启动一个NGINX container,模拟cluster外部的服务,待会儿我们通过endpoints把这个服务关联进来。最终,我们可以在cluster内部通过my-external-service访问外部的NGINX服务。
172.16.17.7启动1个NGINX container:
[root@guoxin7 ~]# hostname -I 172.16.17.7 172.17.0.1 192.168.49.1 [root@guoxin7 ~]# docker run --name mynginx -p 8888:80 -itd nginx Unable to find image 'nginx:latest' locally ... Status: Downloaded newer image for docker.io/nginx:latest 2ac149aef6cf7a5a233878b64a25c707c358d6047d2daf5c9a52bf8bdc67a675 [root@guoxin7 ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 2ac149aef6cf nginx "/docker-entrypoin..." 2 minutes ago Up 2 minutes 0.0.0.0:8888->80/tcp mynginx [root@guoxin7 ~]#
然后,在我们的cluster机器上确保可以访问到NGINX container服务:
[root@master-node Chapter05]# curl http://172.16.17.7:8888 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> ...
接下来创建我们的endpoints对象:
[root@master-node Chapter05]# pwd
/root/kubernetes-in-action/Chapter05
[root@master-node Chapter05]# cat my-external-service-endpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: my-external-service
subsets:
- addresses:
- ip: 172.16.17.7
ports:
- port: 8888
[root@master-node Chapter05]# kubectl apply -f my-external-service-endpoints.yaml
endpoints/my-external-service created
[root@master-node Chapter05]# kubectl describe svc my-external-service
Name: my-external-service
Namespace: default
Labels: <none>
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.179.130
IPs: 10.96.179.130
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 172.16.17.7:8888 #endpoints出现了在Service里
Session Affinity: None
Events: <none>
[root@master-node Chapter05]# kubectl get endpoints my-external-service
NAME ENDPOINTS AGE
my-external-service 172.16.17.7:8888 24s
[root@master-node Chapter05]# 11.6 通过Service对象来访问外部服务
前面,我们看到Service的IP是10.96.179.130,它的端口是80。我们通过这个Service对象来访问cluster外部的NGINX服务。
[root@master-node Chapter05]# curl http://10.96.179.130 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ... </html> [root@master-node Chapter05]#
发现可以正常访问外部的服务。此外,我们也可以从当前cluster中的pod内部来访问这个cluster外部的服务:
[root@master-node Chapter05]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-4mwx6 1/1 Running 0 7d20h kubia-htskq 1/1 Running 0 7d20h kubia-nt72z 1/1 Running 0 7d20h [root@master-node Chapter05]# kubectl exec kubia-4mwx6 -it -- /bin/bash root@kubia-4mwx6:/# hostname kubia-4mwx6 root@kubia-4mwx6:/# curl http://10.96.179.130 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> ...
11.7 Service和endpoints的关系?
endpoints的出现,解耦了Service和Pod的关系。从describe Service命令中,也可以看到endpoints的信息。但是,endpoints并不隶属于Service资源对象,它是可以单独于Service而创建出来的。
endpoints的出现,用来解耦Service资源对象和pod是非常有必要的。为什么这么说呢?比方说,当我们想从Kubernetes cluster内部访问一个位于cluster外部的服务的时候,我们在cluster内部创建1个指向外部服务的Service资源对象时,我们是无法给这个Service资源对象指定pod selector,进而让其和提供此服务的pod对应的。我们怎么知道提供这个外部的服务程序是跑在pod上的,还是1个普通的应用程序呢?
12 Service discovery是怎么实现的?
至此,我们已经在Kubernetes cluster中创建了不同类型的Service,并且验证了可以正常访问这些服务。那么,Kubernetes cluster中的服务发现是如何实现的呢?
在Kubernetes中有两种方式来实现Service discovery:
- 环境变量;
- 内置提供DNS功能的Service对象;
12.1 环境变量实现Service discovery
在Kubernetes里,每个pod里都有若干个环境变量,其中就有几个比较特殊的环境变量,用来标识系统中的服务对象的。{SVCNAME}SERVICE_HOST 表示服务IP;
{SVCNAME}_SERVICE_PORT表示服务端口;
其中{SVCNAME}表示系统中已有的服务名,比如系统中有个名为kubernetes的Service资源对象:
[root@master-node Chapter05]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23d #已经运行23天 kubia ClusterIP 10.101.149.183 <none> 80/TCP 9d kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 9d my-external-service ClusterIP 10.96.179.130 <none> 80/TCP 47h #启动运行47小时 [root@master-node Chapter05]#
这里,看到kubernetes 的IP地址和端口分别是:10.96.0.1和443/TCP
那么pod的环境变量就是KUBERNETES_SERVICE_PORT和KUBERNETES_SERVICE_HOST。
我们进入1个pod中,来验证它的环境变量:
[root@master-node Chapter05]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-4mwx6 1/1 Running 0 9d kubia-htskq 1/1 Running 0 9d kubia-nt72z 1/1 Running 0 9d #才运行9天,后于kubernetes对象创建,所以它可以通过环境变量发现kubernets服务对象 [root@master-node Chapter05]# kubectl exec kubia-nt72z -it -- /bin/bash root@kubia-nt72z:/# env NODE_VERSION=7.9.0 HOSTNAME=kubia-nt72z KUBERNETES_PORT_443_TCP_PORT=443 KUBERNETES_PORT=tcp://10.96.0.1:443 TERM=xterm KUBERNETES_SERVICE_PORT=443 #服务的环境变量 KUBERNETES_SERVICE_HOST=10.96.0.1 #服务的环境变量 NPM_CONFIG_LOGLEVEL=info PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin PWD=/ SHLVL=1 HOME=/root YARN_VERSION=0.22.0 KUBERNETES_PORT_443_TCP_PROTO=tcp KUBERNETES_SERVICE_PORT_HTTPS=443 KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1 KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443 _=/usr/bin/env root@kubia-nt72z:/#
因此,我们说pod kubia-nt72z通过它的环境变量发现了服务kubernetes。
但是,这种方式有一个弊端,那就是,要求Service必须要先于pod创建出来,后创建的pod才知道已经存在的Service对象。这里的例子看到kubernetes先于kubia-nt72z创建出来,它可以被pod通过环境变量来发现服务没问题。
比如上例中,我们在它的环境变量中,并没有发现my-external-service这个服务对象的环境变量。但是,我们再手工创建一个pod(/root/kubernetes-in-action/Chapter03/kubia-manual.yaml)出来,它的创建要晚于my-external-service这个服务对象,那么它的环境变量中,就会包含进来了。
[root@master-node Chapter05]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-4mwx6 1/1 Running 0 9d kubia-htskq 1/1 Running 0 9d kubia-manual 1/1 Running 0 5h39m #我晚于my-external-service创建出来,所有我的环境变量里有它 kubia-nt72z 1/1 Running 0 9d [root@master-node Chapter05]# kubectl exec kubia-manual -it -- env PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=kubia-manual TERM=xterm KUBIA_NODEPORT_SERVICE_PORT=80 KUBIA_NODEPORT_PORT=tcp://10.110.90.145:80 .... MY_EXTERNAL_SERVICE_SERVICE_HOST=10.96.179.130 #my-external-service的环境变量 MY_EXTERNAL_SERVICE_PORT_80_TCP_PROTO=tcp KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1 MY_EXTERNAL_SERVICE_PORT_80_TCP_ADDR=10.96.179.130 ...
如果pod比Service先创建出来,那么pod如何发现Service呢?答案是环境变量的方式行不通了。
12.2 内置提供DNS功能的Service对象
通过环境变量的方式,在Kubernetes内部提供服务发现的功能有所限制。于是,Kubernetes的人们研究出了另外一种方式,通过内置一个提供DNS功能的玩意儿,cluster中,一旦新创建1个Service资源对象,你就向我这边注册过来,将来新创建的所有pod,都到我这儿来找服务对象,就能找到你这个Service了。
我们来看一下它实现的原理:
首先,在kube-system中内置1个名为kube-dns的Service资源对象,它随着Kubernetes cluster的启动而启动:
[root@master-node Chapter05]# kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 75d [root@master-node Chapter05]#
然后,系统中所有新建的pod,都在它的/etc/resolv.conf文件中,指向该kube-dns的Service资源对象的cluster IP:
[root@master-node Chapter05]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-4mwx6 1/1 Running 0 9d kubia-htskq 1/1 Running 0 9d kubia-manual 1/1 Running 0 6h4m kubia-nt72z 1/1 Running 0 9d [root@master-node Chapter05]# kubectl exec kubia-nt72z -- cat /etc/resolv.conf nameserver 10.96.0.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 [root@master-node Chapter05]# kubectl exec kubia-manual -- cat /etc/resolv.conf nameserver 10.96.0.10 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 [root@master-node Chapter05]#
从上,我们看到,所有的pod的/etc/resolv.conf文件都指向了10.96.0.10。
我们再来分析一下kube-dns这个Service资源对象:kubectl describe -n kube-system svc kube-dns
[root@master-node Chapter05]# kubectl describe -n kube-system svc kube-dns
Name: kube-dns
Namespace: kube-system
Labels: k8s-app=kube-dns
kubernetes.io/cluster-service=true
kubernetes.io/name=CoreDNS
Annotations: prometheus.io/port: 9153
prometheus.io/scrape: true
Selector: k8s-app=kube-dns
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.0.10
IPs: 10.96.0.10
Port: dns 53/UDP
TargetPort: 53/UDP
Endpoints: 10.244.1.3:53,10.244.2.210:53
Port: dns-tcp 53/TCP
TargetPort: 53/TCP
Endpoints: 10.244.1.3:53,10.244.2.210:53
Port: metrics 9153/TCP
TargetPort: 9153/TCP
Endpoints: 10.244.1.3:9153,10.244.2.210:9153
Session Affinity: None
Events: <none>
[root@master-node Chapter05]# 这里,我们看到原来kube-system下的kube-dns这个Service自己也是通过endpoints来和10.244.1.3:53,10.244.2.210:53关联起来的。那么这个endpoints(10.244.1.3:53,10.244.2.210:53)指向的是什么呢?
[root@master-node Chapter05]# kubectl get pods -n kube-system -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-6d8c4cb4d-bzlc5 1/1 Running 0 26h 10.244.2.210 node-2 <none> <none> coredns-6d8c4cb4d-nnbxg 1/1 Running 0 75d 10.244.1.3 node-1 <none> <none> ...
原来是运行在kube-system下的2个pods。再看一下这个pod的详细信息:
[root@master-node Chapter05]# kubectl describe pod -n kube-system coredns-6d8c4cb4d-bzlc5
Name: coredns-6d8c4cb4d-bzlc5
Namespace: kube-system
Priority: 2000000000
Priority Class Name: system-cluster-critical
Node: node-2/172.16.11.161
Start Time: Wed, 23 Mar 2022 11:40:55 +0800
Labels: k8s-app=kube-dns
pod-template-hash=6d8c4cb4d
Annotations: <none>
Status: Running
IP: 10.244.2.210
IPs:
IP: 10.244.2.210
Controlled By: ReplicaSet/coredns-6d8c4cb4d #pod被上层的ReplicaSet管控
Containers:
....从上看到,它是属于ReplicaSet/coredns-6d8c4cb4d 管控的:
[root@master-node Chapter05]# kubectl get rs -n kube-system
NAME DESIRED CURRENT READY AGE
coredns-6d8c4cb4d 2 2 2 75d
[root@master-node Chapter05]# kubectl describe rs -n kube-system
Name: coredns-6d8c4cb4d
Namespace: kube-system
Selector: k8s-app=kube-dns,pod-template-hash=6d8c4cb4d
Labels: k8s-app=kube-dns
pod-template-hash=6d8c4cb4d
Annotations: deployment.kubernetes.io/desired-replicas: 2
deployment.kubernetes.io/max-replicas: 3
deployment.kubernetes.io/revision: 1
Controlled By: Deployment/coredns #ReplicaSet被上层的Deployment管控
Replicas: 2 current / 2 desired
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: k8s-app=kube-dns
pod-template-hash=6d8c4cb4d而ReplicaSet/coredns-6d8c4cb4d 这个ReplicaSet又被Deployment/coredns管控:
[root@master-node Chapter05]# kubectl get deployments.apps -n kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 75d [root@master-node Chapter05]# kubectl describe deployments.apps -n kube-system coredns Name: coredns Namespace: kube-system CreationTimestamp: Fri, 07 Jan 2022 17:11:49 +0800 Labels: k8s-app=kube-dns Annotations: deployment.kubernetes.io/revision: 1 Selector: k8s-app=kube-dns Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable StrategyType: RollingUpdate
到了Deployment层就结束了。我们暂时还没有学习和了解Kubernetes里的Deployment,我们在后面会单独研究它。
总结一下,Kubernetes通过内置的dns实现服务发现的方式是这样的,起了一个Deployment名为coredns,它管控了一个ReplicaSet:coredns-6d8c4cb4d,这个ReplicaSet管控了2个pod:coredns-6d8c4cb4d-bzlc5和coredns-6d8c4cb4d-nnbxg 。然后,创建了一个cluster IP类型的Service对象叫做:kube-dns,一个同名的endpoints,指向了那2个pods。
从上,看到coredns-6d8c4cb4d-bzlc5和coredns-6d8c4cb4d-nnbxg 的生命周期不同,1个是26h,一个是75d。其中一个是我特意手工杀掉之后,由Deployment自动帮我启动的一个新的pod出来之后的结果。这也验证了Kubernetes的强大,
13 Service的sessionAffinity
13.1 什么是Service的sessionAffinity?
从名字上,我们大概猜测到,就是给Service资源对象设置”会话亲和性”。具体啥意思呢?就是说,当客户端会话每次请求访问我这个Service对象的时候,我每次都是以某个特定的pod来响应你,还是从我这个Service对象中的endpoints里任意挑选1个pod来响应你。
“碗里有3个蛋,每次都随机挑选1个吃,还是每次都吃最大的那一个。”
13.2 sessionAffinity的作用和应用场景?
- 作用:简而言之,就是可以限定客户端的服务请求,每次都打到后端的某个特定的pod上,而不是随机一个pod来响应来自同一个客户端的请求。
- 应用场景:对于某些特定的load balancer的场景,我们希望特定的会话每次都到特定的后端服务,可以命中缓存,提高效率。
13.3 Service支持的sessionAffinity类型有哪些?
Kubernetes里的Service目前只支持两种类型的sessionAffinity:None(默认值),ClientIP。
13.4不同类型的sessionAffinity的区别是什么?
默认情况下None类型的sessionAffinity,表示Service资源对象,不对特定客户端发起的Service请求进行限定和区分,而是随机挑选1个pod响应;
ClientIP:服务端会根据客户端的IP,经过特定的算法,从endpoints中选定1个pod响应该会话,而且以后每次该客户端发来的请求,都是该pod来响应。当然,不同IP的client发起的请求,可能由不同的pod来响应。
13.5 如何查看|修改|设置、验证Service的sessionAffinity?
查看Service的sessionAffinity:
[root@master-node ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24d kubia ClusterIP 10.101.149.183 <none> 80/TCP 10d kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 10d my-external-service ClusterIP 10.96.179.130 <none> 80/TCP 2d22h [root@master-node ~]# kubectl describe svc kubia Name: kubia Namespace: default Labels: <none> Annotations: <none> Selector: app=kubia Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.101.149.183 IPs: 10.101.149.183 Port: <unset> 80/TCP TargetPort: 8080/TCP Endpoints: 10.244.1.20:8080,10.244.2.198:8080,10.244.2.199:8080 Session Affinity: None #这里就是Service的sessionAffinity,默认值是None。 Events: <none> [root@master-node ~]#
验证None类型的sessionAffinity,每次请求都到不同的pod上去了:
[root@master-node ~]# curl http://10.101.149.183 You've hit kubia-htskq [root@master-node ~]# curl http://10.101.149.183 You've hit kubia-4mwx6 [root@master-node ~]# curl http://10.101.149.183 You've hit kubia-nt72z [root@master-node ~]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-4mwx6 1/1 Running 0 10d kubia-htskq 1/1 Running 0 10d kubia-manual 1/1 Running 0 28h kubia-nt72z 1/1 Running 0 10d [root@master-node ~]#
修改|设置Service的sessionAffinity为ClientIP:
[root@master-node ~]# kubectl edit svc kubia
...
selector:
app: kubia
sessionAffinity: ClientIP #None改为ClientIP,保存退出即可
type: ClusterIP
... 验证ClientIP类型的sessionAffinity,每次请求都到同1个pod上去了:
[root@master-node ~]# kubectl describe svc kubia Name: kubia ... IP: 10.101.149.183 IPs: 10.101.149.183 Port: <unset> 80/TCP TargetPort: 8080/TCP Endpoints: 10.244.1.20:8080,10.244.2.198:8080,10.244.2.199:8080 Session Affinity: ClientIP #类型为SessionAffinity Events: <none> [root@master-node ~]# curl http://10.101.149.183 You've hit kubia-htskq [root@master-node ~]# curl http://10.101.149.183 You've hit kubia-htskq [root@master-node ~]# curl http://10.101.149.183 You've hit kubia-htskq [root@master-node ~]# #从其它client向kubia发起Service请求: [root@node-1 ~]# curl http://10.101.149.183 You've hit kubia-nt72z [root@node-1 ~]# curl http://10.101.149.183 You've hit kubia-nt72z [root@node-1 ~]# curl http://10.101.149.183 You've hit kubia-nt72z [root@node-1 ~]#
对于类型为ClientIP的sessionAffinity,不同IP的客户端,访问到的pod不同,但是同1个IP的client,每次请求都到同1个pod。
14 Service的externalTrafficPolicy属性
前面,我们介绍了Service的sessionAffinity属性,它对所有类型(cluster IP,node port,Loadbalancer,ingress)的Service都生效。接下来,我们来看Service的另外一种属性,externalTrafficPolicy,它只针对node port及以上类型的Service资源对象有效。
14.1 externalTrafficPolicy的作用?
对于pod中的container,如果它提供的服务被来自于cluster内部的其它pod访问的话,它是知道对方的IP地址的。如果,来自于cluster外部的客户端访问Service(访问node port或者Loadbalancer类型的Service),那么底层的pod中的container是看不到访问源头的IP地址的。此时,如果想要看到访问源头的IP地址的话,需要设置Service对象的externalTrafficPolicy属性。
14.2 externalTrafficPolicy的类型有哪些?
- Cluster:默认值。看到的访问源头IP不准确,有可能会导致服务请求的二次跳转,但是可以提供较好的Load balance,即会把访问请求均衡的分散到后端的pod上,不会导致服务请求失败
- Local:保留了访问源头的IP地址,不会导致服务请求的二次跳转,不能保证较好的load balance,可能导致服务请求失败。
14.3 externalTrafficPolicy的生效范围
它只对node port及以上类型的Service资源对象有效。cluster IP类型的Service没有该属性值。
14.4 externalTrafficPolicy举例说明
- 场景1:当前有2个node:node1,node2 ;3个pods:pod-a,pod-b,pod-c,其中pod-a和pod-b运行在node1上,pod-c运行在node2上,我们的服务类型是node port的。
当externalTrafficPolicy=Local,我们通过node_ip+端口的方式访问服务的话,则可能出现node1和node2分别承担50%的请求,但是到pod上,则是pod-a和pod-b各承担25%,pod-c承担了50%。
当externalTrafficPolicy=Cluster时,则不存在上述问题。
- 场景2:另外,当我们的3个如果都在node1上,node2上没有运行pod。
如果externalTrafficPolicy=Local,当通过node2的IP+端口来访问服务时,则出现尴尬,发现访问服务失败,请求hang住,因为本地node上没有任何pod;
如果externalTrafficPolicy=Local,当通过node2的IP+端口来访问服务时,则访问成功,但是此时,底层服务调用发生了二次跳转,因为本地node2没有pod,转而把请求转到node1上的pod。
14.5 如何查看|修改|设置|验证Service的externalTrafficPolicy
查看:
[root@master-node ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 24d kubia ClusterIP 10.101.149.183 <none> 80/TCP 10d kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 10d my-external-service ClusterIP 10.96.179.130 <none> 80/TCP 3d [root@master-node ~]# kubectl describe svc kubia-nodeport Name: kubia-nodeport Namespace: default Labels: <none> Annotations: <none> Selector: app=kubia Type: NodePort IP Family Policy: SingleStack IP Families: IPv4 IP: 10.110.90.145 IPs: 10.110.90.145 Port: <unset> 80/TCP TargetPort: 8080/TCP NodePort: <unset> 30123/TCP Endpoints: 10.244.1.20:8080,10.244.2.198:8080,10.244.2.199:8080 Session Affinity: None External Traffic Policy: Cluster #nodeport类型Service的externalTrafficPolicy默认值是cluster Events: <none> [root@master-node ~]# kubectl get pods -owide #3个pod分别在node1和node2上,master node上没有任何pod NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-4mwx6 1/1 Running 0 10d 10.244.2.198 node-2 <none> <none> kubia-htskq 1/1 Running 0 10d 10.244.2.199 node-2 <none> <none> kubia-manual 1/1 Running 0 30h 10.244.2.209 node-2 <none> <none> kubia-nt72z 1/1 Running 0 10d 10.244.1.20 node-1 <none> <none> [root@master-node ~]#
此时,我们的客户端可以通过当前cluster的任意节点IP+port来访问服务:
$ curl http://172.16.11.161:30123 You've hit kubia-nt72z asher at MacBook-Air-3 in ~ $ curl http://172.16.11.168:30123 You've hit kubia-4mwx6 asher at MacBook-Air-3 in ~ $ curl http://172.16.11.148:30123 You've hit kubia-nt72z asher at MacBook-Air-3 in ~ $
修改:
[root@master-node ~]# kubectl edit svc kubia-nodeport ... externalTrafficPolicy: Local #改为Local,保存退出。 ...
验证externalTrafficPolicy: Local :
$ curl http://172.16.11.148:30123 You've hit kubia-nt72z asher at MacBook-Air-3 in ~ $ curl http://172.16.11.161:30123 You've hit kubia-htskq asher at MacBook-Air-3 in ~ $ curl http://172.16.11.168:30123 curl: (28) Failed to connect to 172.16.11.168 port 30123: Operation timed out # 此时,服务请求被挂住了,
此时,由于底层的3个pod分别运行在2个worker node上,没有任何pod运行在master node 172.16.11.168机器上,那么通过curl http://172.16.11.168:30123 将被阻塞,挂住了。
14.6 参考
15 Pod的readiness probe
在前面的第四章,我们学习和使用了pod的liveness probe来保证pod是健康运行状态的。接下来,我们看pod的另外一种probe:readiness probe。
15.1 我们为什么需要readiness probe及它的使用场景是什么
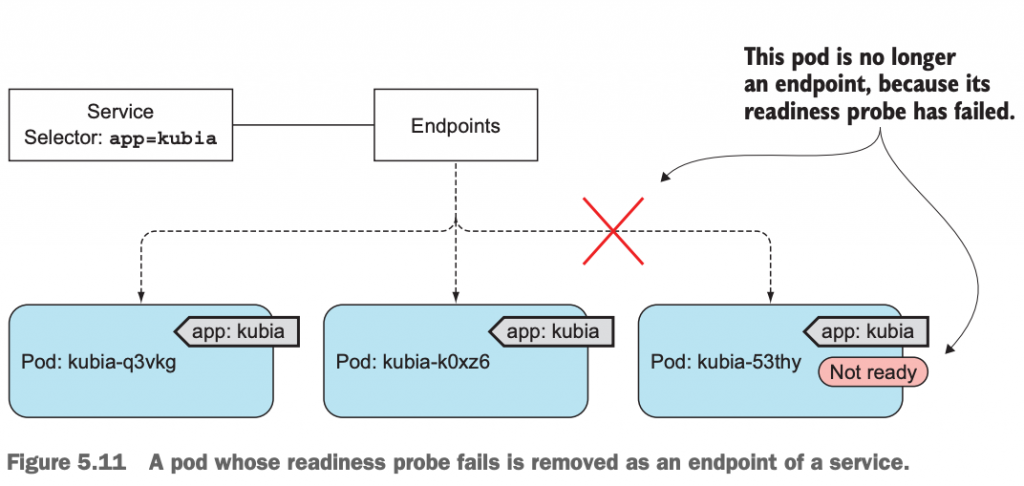
我们知道了,Service通过label selector把满足条件的pod当作它的endpoints,这样就形成了访问Service时,其实是访问底层的pod的架构。那么试想,如果当前Service的endpoints里添加了1个新的pod,在这个pod还没有完全启动成功,如果有客户端的访问请求被路由到这个新的pod上了。结果会怎样呢?
结果就是,在pod完全启动结束之前,这个客户端的请求被hang住了,好像并没有得到任何响应一样。我们当然不希望这种情况出现。我们希望这时的客户端请求要么被路由到已有的pod上,有么在新的pod完全启动成功之前,不响应客户端的服务请求。
于是,Kubernetes的开发者引入了一个新的readiness probe,用于检测该pod是否正常启动并可以对外提供服务。用来确保pod在启动结束之前,不对外提供服务。
15.2 readiness probe的3种工作方式
跟前面提到的pod中container的liveness probe一样的3种工作方式:
- HTTP Get probe:向pod中的container发送一个HTTP请求,如果返回正常,就认为container是正常的,该pod可以接受服务请求;否则,不能接受服务请求;
- TCP socket probe:跟HTTP类似,向pod中的container建立1个TCP socket连接,成功则pod可以接受服务;否则,不行;
- Exec probe:在pod中的container里执行某个特定的命令,根据命令执行结果是否成功来判断pod是否可以接收服务请求;
15.3 如何创建|使用|验证带有readiness probe的pod
在pod的container中设置readiness probe跟设置liveness probe的方式几乎没有差别,无非是把关键字从livenessProbe改为readinessProbe。
先看一个container中有readinessProbe的ReplicaSet的代码:
[root@master-node Chapter05]# pwd
/root/kubernetes-in-action/Chapter05
[root@master-node Chapter05]# cat kubia-rc-readinessprobe.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 3
selector:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- name: http
containerPort: 8080
readinessProbe: #container中probe的关键字
exec: #exec类型的探测方式,如果container中ls /var/ready命令执行成功,则container可以接收服务请求,否则,container不是ready状态
command:
- ls
- /var/ready
[root@master-node Chapter05]# 创建这个ReplicationController,并查看pod的状态:
[root@master-node Chapter05]# kubectl get rc No resources found in default namespace. [root@master-node Chapter05]# kubectl apply -f kubia-rc-readinessprobe.yaml replicationcontroller/kubia created [root@master-node Chapter05]# kubectl get rc NAME DESIRED CURRENT READY AGE kubia 3 3 0 5s [root@master-node Chapter05]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-4mwx6 1/1 Running 0 11d kubia-76v4r 0/1 Running 0 8s kubia-8chrc 0/1 Running 0 8s kubia-htskq 1/1 Running 0 11d kubia-manual 1/1 Running 0 2d3h kubia-nt72z 1/1 Running 0 11d kubia-wfpc4 0/1 Running 0 8s [root@master-node Chapter05]#
这里,看到pods的READY列中,始终没有正常的。原因何在,新建的这3个pod,它的container中的readiness probe执行失败,所以,看到pod的状态不是ready的。
执行kubectl describe pod kubia-76v4r 来验证:
[root@master-node Chapter05]# kubectl describe pod kubia-76v4r Name: kubia-76v4r Namespace: default Priority: 0 Node: node-2/172.16.11.161 Start Time: Fri, 25 Mar 2022 15:04:34 +0800 ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m5s default-scheduler Successfully assigned default/kubia-76v4r to node-2 Normal Pulling 2m4s kubelet Pulling image "luksa/kubia" Normal Pulled 2m1s kubelet Successfully pulled image "luksa/kubia" in 2.777117726s Normal Created 2m1s kubelet Created container kubia Normal Started 2m1s kubelet Started container kubia Warning Unhealthy 6s (x15 over 118s) kubelet Readiness probe failed: ls: cannot access /var/ready: No such file or directory [root@master-node Chapter05]#
Warning Unhealthy 6s (x15 over 118s) kubelet Readiness probe failed: ls: cannot access /var/ready: No such file or directory说明,该pod不是正常状态的原因。
我们进入该pod中,手工touch对应的文件:
[root@master-node Chapter05]# kubectl exec kubia-76v4r -it -- /bin/bash root@kubia-76v4r:/# ls -l /var/ready ls: cannot access /var/ready: No such file or directory root@kubia-76v4r:/# touch /var/ready root@kubia-76v4r:/# exit exit [root@master-node Chapter05]# kubectl get pods kubia-76v4r NAME READY STATUS RESTARTS AGE kubia-76v4r 1/1 Running 0 4m48s [root@master-node Chapter05]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-4mwx6 1/1 Running 0 11d kubia-76v4r 1/1 Running 0 4m52s #此时,pod状态变为ready kubia-8chrc 0/1 Running 0 4m52s kubia-htskq 1/1 Running 0 11d kubia-manual 1/1 Running 0 2d3h kubia-nt72z 1/1 Running 0 11d kubia-wfpc4 0/1 Running 0 4m52s [root@master-node Chapter05]#
15.4 readiness和liveness probe的区别和联系
liveness probe如果发现container异常,它会主动杀死并重启container;而readiness probe既不会杀死container,也不会重启container;
liveness probe不会等待readiness probe执行成功之后再开始探测container是否健康;如果想要控制liveness probe在container启动一会儿之后,再来执行探测container是否健康运行的话,那么需要设置一个liveness probe的参数,initialDelaySeconds。
15.5 官方文档参考Define readiness probes
官方文档参考:Define readiness probes
16 Service故障诊断tips
16.1 永远不要去ping service_ip
通常我们诊断网络是否可达的方式是ping target_IP;但是,在Kubernetes里,我们去验证某个服务是否可用正常访问的时候,不要第一时间想到ping service_ip;那样的话,你永远ping不通,而要用curl service_ip;比如:
[root@master-node ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 25d kubia ClusterIP 10.101.149.183 <none> 80/TCP 11d kubia-nodeport NodePort 10.110.90.145 <none> 80:30123/TCP 11d my-external-service ClusterIP 10.96.179.130 <none> 80/TCP 3d23h [root@master-node ~]# ping 10.101.149.183 PING 10.101.149.183 (10.101.149.183) 56(84) bytes of data. ^C --- 10.101.149.183 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1000ms [root@master-node ~]# curl 10.101.149.183 You've hit kubia-nt72z [root@master-node ~]#
再比如,我在前面创建的Oracle cloud Kubernetes环境的那个Loadbalancer IP依然这样,ping不通,但是可以正常访问服务。
$ ping 168.138.55.28
PING 168.138.55.28 (168.138.55.28): 56 data bytes
Request timeout for icmp_seq 0
Request timeout for icmp_seq 1
^C
--- 168.138.55.28 ping statistics ---
3 packets transmitted, 0 packets received, 100.0% packet loss
asher at MacBook-Air-3 in ~
$ curl 168.138.55.28
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Welcome to Oracle Kubernetes Engine!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Oracle Kubernetes Engine!</h1>
<p>部署在Oracle云亚太区数据中心上的Kubernetes LoadBalancer服务</p>
<p>触手可及,一起来玩
<a href="http://www.knockatdatabase.com/">by 数据库敲门人</a>.<br/>
</p>
</body>
</html>
asher at MacBook-Air-3 in ~
$ 16.2 Service不可访问的可能原因
是否是正确的访问Service的port,而不是去访问其底层的pod的port;
底层pod是否在Service的endpoints列表里;
底层pod的readiness probe是否执行成功,即pod是否是ready状态;
17 本地Kubernetes cluster安装配置使用ingress
17.1 准备images和资源的yaml文件
docker pull registry.cn-hangzhou.aliyuncs.com/yutao517/ingress_nginx_controller:v1.1.0 docker tag registry.cn-hangzhou.aliyuncs.com/yutao517/ingress_nginx_controller:v1.1.0 k8s.gcr.io/ingress-nginx/controller:v1.1.1 docker pull registry.cn-hangzhou.aliyuncs.com/yutao517/kube_webhook_certgen:v1.1.1 docker tag registry.cn-hangzhou.aliyuncs.com/yutao517/kube_webhook_certgen:v1.1.1 k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1 wget https://download.yutao.co/mirror/deploy.yaml 修改其中的328行,修改其image为image: k8s.gcr.io/ingress-nginx/controller:v1.1.1而不是作者源文件中的v1.1.0。 [root@master-node ~]# mkdir local_nginx_ingress [root@master-node ~]# cd local_nginx_ingress/ [root@master-node local_nginx_ingress]# wget https://download.yutao.co/mirror/deploy.yaml
17.2 创建world namespace和configmap以及Deployment资源对象
[root@master-node local_nginx_ingress]# cat asia.deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2022-12-12T08:22:51Z"
generation: 1
labels:
app: asia
name: asia
namespace: world
resourceVersion: "1298"
uid: 34afb7cc-9b30-4243-95b4-b39d0b893090
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app: asia
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: asia
spec:
containers:
- image: nginx:1.21.5-alpine
imagePullPolicy: IfNotPresent
name: c
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/nginx/html
name: html
- mountPath: /etc/nginx
name: nginx-conf
readOnly: true
dnsPolicy: ClusterFirst
initContainers:
- command:
- sh
- -c
- echo 'hello, you reached ASIA' > /html/index.html
image: busybox:1.28
imagePullPolicy: IfNotPresent
name: init-container
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /html
name: html
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: html
- configMap:
defaultMode: 420
items:
- key: nginx.conf
path: nginx.conf
name: nginx-conf
name: nginx-conf
[root@master-node local_nginx_ingress]#
[root@master-node local_nginx_ingress]# cat europe.deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2022-12-12T08:22:51Z"
generation: 1
labels:
app: europe
name: europe
namespace: world
resourceVersion: "1300"
uid: 131fc90c-7ad9-4d9e-be4c-248486ddfab5
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app: europe
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: europe
spec:
containers:
- image: nginx:1.21.5-alpine
imagePullPolicy: IfNotPresent
name: c
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/nginx/html
name: html
- mountPath: /etc/nginx
name: nginx-conf
readOnly: true
dnsPolicy: ClusterFirst
initContainers:
- command:
- sh
- -c
- echo 'hello, you reached EUROPE' > /html/index.html
image: busybox:1.28
imagePullPolicy: IfNotPresent
name: init-container
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /html
name: html
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: html
- configMap:
defaultMode: 420
items:
- key: nginx.conf
path: nginx.conf
name: nginx-conf
name: nginx-conf
[root@master-node local_nginx_ingress]#
[root@master-node local_nginx_ingress]# kubectl create namespace world
namespace/world created
[root@master-node local_nginx_ingress]# kubectl apply -f nginx-conf-configmap.yaml
configmap/nginx-conf created
[root@master-node local_nginx_ingress]# kubectl apply -f asia.deployment.yaml
deployment.apps/asia created
[root@master-node local_nginx_ingress]# kubectl apply -f europe.deployment.yaml
deployment.apps/europe created
[root@master-node local_nginx_ingress]#
[root@master-node local_nginx_ingress]# kubectl -n world get all
NAME READY STATUS RESTARTS AGE
pod/asia-6644cdddb9-g8k6s 1/1 Running 0 51s
pod/asia-6644cdddb9-r7jpf 1/1 Running 0 51s
pod/europe-866945bcbf-4r44q 1/1 Running 0 10s
pod/europe-866945bcbf-92f25 1/1 Running 0 10s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/asia 2/2 2 2 51s
deployment.apps/europe 2/2 2 2 10s
NAME DESIRED CURRENT READY AGE
replicaset.apps/asia-6644cdddb9 2 2 2 51s
replicaset.apps/europe-866945bcbf 2 2 2 10s
[root@master-node local_nginx_ingress]# 参考:Kubernetes(十六)—国内安装Ingress-nginx服务
18小结
在本章,我们学习了:
Service资源对象是什么,它能帮我们解决什么问题;
Service资源对象和pod的关联关系,endpoints如何解耦Service和pod;
如何创建|使用|验证cluster IP|node port|Loadbalancer|ingress类型的Service资源对象;
学习和掌握Service资源对象的底层实现原理;
掌握Service discovery的实现方式
如何设置pod中container的readiness probe