Kubernetes in Action读书笔记第四章:ReplicationController和其它控制器
本章主要内容
- 学会如何通过liveness探针来保持pod的健康运行;
- 了解我们为什么需要ReplicationController,以及如何使用它,它有哪些特征和优势(运行同一个pod的多个副本/自动重新调度pod来应对节点故障的情形/快速水平扩展pod等);
- 如何运行和使用不同类型的控制器:ReplicaSet、DaemonSet、Job、CronJob
在前面的章节里,我们学会了如何创建、删除和运行pod。但是由于我们创建的pod是被调度到node上运行的,如果pod所在node出现故障了,那么这个pod将不会被重新调度。那么结果就是原本这个pod提供的服务将受到影响,显然这是不能接受的。我们希望类似于这种情况发生时,我们的pod可以被重新调度,它对外提供的服务不受影响。那么该怎么办呢?于是,人们引进了控制器和Deployment来解决该问题。所谓的控制器和Deployment我们可以理解是在pod之上再抽象了一层,我们告诉Kubernetes我们需要控制器或者是Deployment,然后由这些控制器或者Deployment帮我们去创建和管理pod,而不应该由我们直接去创建管理和维护pod,即使pod是Kubernetes里的最小管理和维护单位。结果就是,如果node出现故障的话,这些控制器和Deployment会自动重新帮我们拉取并运行pod。
在开始讨论控制器和Deployment之前,我们先看看如何保证pod自己的健康运行?也就是说先不考虑资源不够,或者是pod所在node出现故障等情形导致pod故障的场景下。我们仅把目光注视在pod自身上。
Contents
- 1 1如何使用liveness探针来保证pod健康
- 2 2 ReplicationController
- 2.1 2.1 什么是ReplicationController及其作用?
- 2.2 2.2 ReplicationController和ReplicaSet是什么关系?
- 2.3 2.3 如何创建ReplicationController?
- 2.4 2.4 如何查看ReplicationController
- 2.5 2.5 构成ReplicationController的3元素
- 2.6 2.6 验证ReplicationController水平扩展pod的场景
- 2.7 2.7 ReplicationController水平扩展pod的底层原理
- 2.8 2.8 ReplicationController自动维护pod的场景验证
- 2.9 2.9 ReplicationController和pod之间的关联关系是什么?
- 2.10 2.10 手工修改pod的label使其脱离ReplicationController的场景和后果?
- 2.11 2.11手工修改ReplicationController的label selector结果是?
- 2.12 2.12如何修改ReplicationController的pod template模板字段及其应用场景
- 2.13 2.13 只删除ReplicationController不删除它管理的pod
- 3 3 ReplicaSet控制器
- 4 4 DaemonSet控制器
- 5 5 Job资源控制器
- 5.1 5.1 什么是Job资源
- 5.2 5.2 我们为什么需要Job
- 5.3 5.3 Job的特征是什么
- 5.4 5.4 Job有哪些类型
- 5.5 5.5 普通pod,ReplicaSet和Job对比
- 5.6 5.6 如何创建和使用job
- 5.7 5.7 演示Job管理的pod在执行过程中被杀死的场景
- 5.8 5.8 修改Job中pod的restartPolicy=Always
- 5.9 5.9串行job示例
- 5.10 5.10并行job示例
- 5.11 5.11 设置Job执行时长上限
- 5.12 5.12 删除job
- 5.13 5.13 设置Job执行成功之后自动删除示例
- 5.14 5.14 为什么Job执行成功之后不会自动删除
- 6 6 CronJob资源控制器
- 7 7 ReplicationController、ReplicaSet、DaemonSet、Job、CronJob对比
- 8 8 小结
- 9 9 本章思维导图
1如何使用liveness探针来保证pod健康
1.1 liveness探针能解决什么问题
我们知道,pod是在container之上封装的对象,pod的监控运行其实要保证其内部的container正常运行。可是container难免会出现故障,比如程序死循环、OOM(Out Of Memory)、对服务请求失去响应假死等异常。试想如果这些运行在pod中的container出现这些故障之后,从外部看来好像都是正常的,但是它们已经失去了对外提供服务的能力。所以,人们引入了一个liveness的探针,用来持续监控运行在pod中的container的监控状况。见名知意,存活探针。从container内部周期性的监控它是否健康,如果出现异常,则采取相应的处理措施,比如重启container。
1.2 liveness probe的作用范围
liveness probe是作用在运行于pod中的container之上的,而不是针对pod本身。
1.3 liveness probe的工作方式和原理
liveness probe有3种方式来监控container的健康状况:
发送HTTP GET请求:向container的IP和端口,以及指定path发送1个HTTP的get请求,收到正常响应(比如200,3xx的响应码)则认为container OK。否则,收到其它错误码,或者压根儿就没收到响应,则认为container故障了,就尝试重启它。
建立TCP会话连接:和container的指定port建立1个TCP会话,如果成功,则认为container是OK的,否则container故障,重启它。
执行特定命令:在container内部执行特定的命令,如果命令返回结果状态代码是0则认为container是OK,否则就重启container。
1.4 基于HTTP GET的liveness probe例子
代码基于前面例子的app.js的container做了改进,换成了luksa/kubia-unhealthy的image,运行之后,该container前5次对外服务响应正常,之后就抛出500错误。然后,我们在container上加了1个基于HTTP GET请求的liveness,一旦它探测到container故障,则重启它。
1.4.1 代码及解读
代码如下:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat kubia-liveness-probe.yaml
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe:
httpGet:
path: /
port: 8080
[root@master-node Chapter04]# 我们可以从yaml文件中的containers部分,多了一个探针,访问根路径下的8080端口,看看是不是能获取正常返回。
1.4.2 启动带liveness prode的pod
启动该pod:
[root@master-node Chapter04]# kubectl get pods No resources found in default namespace. [root@master-node Chapter04]# kubectl apply -f kubia-liveness-probe.yaml pod/kubia-liveness created [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-liveness 0/1 ContainerCreating 0 3s [root@master-node Chapter04]#
1.4.3验证liveness重启container的功能
过一段儿时间之后,看到pod的状态发生变化:
[root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-liveness 1/1 Running 0 2m50s [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-liveness 1/1 Running 0 3m5s 10.244.2.42 node-2 <none> <none> [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-liveness 1/1 Running 1 (17s ago) 3m37s 10.244.2.42 node-2 <none> <none> [root@master-node Chapter04]#
随着时间的推移,kubectl get pods命令结果中的RESTARTS 不断变大,说明pod中的container被不断重启了。当然,我们也可以根据提示信息,到对应的node上去核实对应的container的重启情况。
这里通过kubectl describe pod kubia-liveness 获取pod的详细信息,也能看到container被liveness probe重启的信息:
[root@master-node ~]# kubectl describe pod kubia-liveness
Name: kubia-liveness
Namespace: default
Priority: 0
Node: node-2/172.16.11.161
Start Time: Sat, 05 Mar 2022 12:31:19 +0800
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.244.2.42
...
Containers:
kubia:
Container ID: docker://532e8f4c2e6e925b62a49e908608a123338448269d2fb53565950417a580b222
Image: luksa/kubia-unhealthy
Image ID: docker-pullable://docker.io/luksa/kubia-unhealthy@sha256:5c746a42612be61209417d913030d97555cff0b8225092908c57634ad7c235f7
Port: <none>
Host Port: <none>
State: Running
Started: Sat, 05 Mar 2022 12:40:13 +0800
Last State: Terminated
Reason: Error
Exit Code: 137
Started: Sat, 05 Mar 2022 12:38:22 +0800
Finished: Sat, 05 Mar 2022 12:40:09 +0800
Ready: True
Restart Count: 4
Liveness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 9m18s default-scheduler Successfully assigned default/kubia-liveness to node-2
Normal Pulled 7m39s kubelet Successfully pulled image "luksa/kubia-unhealthy" in 1m37.018726353s
Normal Pulled 5m55s kubelet Successfully pulled image "luksa/kubia-unhealthy" in 2.770453396s
Normal Created 4m5s (x3 over 7m39s) kubelet Created container kubia
Normal Started 4m5s (x3 over 7m39s) kubelet Started container kubia
Normal Pulled 4m5s kubelet Successfully pulled image "luksa/kubia-unhealthy" in 2.774431705s
Warning Unhealthy 2m48s (x9 over 6m48s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
Normal Killing 2m48s (x3 over 6m28s) kubelet Container kubia failed liveness probe, will be restarted
Normal Pulling 2m18s (x4 over 9m16s) kubelet Pulling image "luksa/kubia-unhealthy"
Normal Pulled 2m15s kubelet Successfully pulled image "luksa/kubia-unhealthy" in 2.739770305s
[root@master-node ~]# 1.4.4 liveness probe的几个参数解读
从上,kubectl describe pod kubia-liveness 看到pod中的container的结果中,退出代码137,Exit Code: 137,表示容器被kill了,发送了kill -9的指令(操作系统上执行:kill -l;查看所有可以发送给进程的信号);
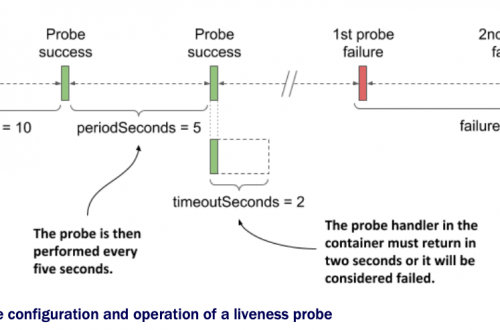
Liveness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3 其中delay=0s表示的是该liveness probe随着container的启动而启动,延迟0s;timeout=1s,表示给container发送HTTP Get请求之后,要求在1s之内返回结果,否则就认为container异常,计数1次;period=10s意味着,每间隔10s就向container发送一次HTTP get请求;#failure=3表示的是连续累计3次异常的计数,就认为container需要被restart了。
实际工作中,我们一般不会把delay参数值设为0s,因为这会让probe跟随container启动而启动,并且立即检测container的监控状况,有可能container会因为系统资源紧张等客观原因而无法响应HTTP get请求,进而造成了probe误伤重启了container。我们可以在pod的yaml文件中通过initialDelaySeconds选项来设置,如下,设置initialDelaySeconds: 15
[root@master-node Chapter04]# cat kubia-liveness-probe-initial-delay.yaml
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 15
[root@master-node Chapter04]# 1.4.5使用liveness probe的建议和小结
生产环境下最好给container都加上该探针,以加强container的真正健康运行;
最好是给HTTP get请求加上1个特定的访问路径,比如访问/your_health_path_here,这样更有针对性的判断container是否正常;且访问的上下文路径不能是需要鉴权的;
探针执行的程序要足够轻量,绝对不能是那些消耗CPU、内存资源太多的”重命令”;
对于基于Java应用的container,最好选择HTTP get的方式,而不要使用exec探测某个执行命令的返回代码来判断;
probe的周期性运行是被worker node上的kubelet组件接管的,而不是master node上的任何组件管理的;
如果worker node整个节点崩溃的话,master node会负责接管这整个worker node上的pod,并把它们调度到其它可用的节点上并重新运行;
如果崩溃的节点上有我们手工创建和管理的pod,那么master node是不会接管这些pod的。如果我们想要pod能被重新调度到其它节点上并被重启的话,我们就得把pod交给ReplicationController或者其它类似的控制器去管理。
2 ReplicationController
2.1 什么是ReplicationController及其作用?
ReplicationController是用来管理pod对象的资源,它可以确保由它管理的pod始终保持在运行的状态。不管是由于pod运行的node节点出现故障还是其它原因导致pod不能正常运行,ReplicationController都可以重新再拉起1个pod并运行起来。
A ReplicationController is a Kubernetes resource that ensures its pods are always kept running. If the pod disappears for any reason, such as in the event of a node disappearing from the cluster or because the pod was evicted from the node, the ReplicationController notices the missing pod and creates a replacement pod.
P122
2.2 ReplicationController和ReplicaSet是什么关系?
ReplicationController是ReplicaSet的前身,现在基本上都使用后者取代前者了。但是,出于学习技术原理的角度出发,我们还是有必要先搞清楚ReplicationController。
2.3 如何创建ReplicationController?
[root@master-node Chapter04]# cat kubia-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 3
selector:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
[root@master-node Chapter04]# kubectl apply -f kubia-rc.yaml
replicationcontroller/kubia created
[root@master-node Chapter04]# 我们定义了一个类型为ReplicationController的对象,其名字是kubia。它管理的pod的副本数有3个,通过replicas字段来指定。它的label selector是app=kubia,意思是它负责管理的pod也必须有这个label。当然,这里也可以不指定ReplicationController的这个label selector,不指定的话,它默认会使用模板里指定的pod的label selector。
接下来的template模板字段用来描述这个ReplicationController所管理的pod的属性的,其中指定了pod的label是app=kubia的pod,这样ReplicationController和pod就串联了起来。template字段中嵌套的spec字段里指定的信息就是pod里运行的container的相关信息了。
最后,我们把这份yaml文件通过kubectl apply -f kubia-rc.yaml 命令提交给Kubernetes的API server之后,Kubernetes会帮我们创建一个名为kubia的ReplicationController出来,并创建3个pod出来。注意,这3个pod是由ReplicationController管控的。
这里用到的pod的label就是前面第三章第3节里讲到给pod贴上label的好处了。
2.4 如何查看ReplicationController
[root@master-node Chapter04]# kubectl get rc NAME DESIRED CURRENT READY AGE kubia 3 3 3 56s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-8dcg5 1/1 Running 0 61s kubia-94mq8 1/1 Running 0 61s kubia-kghvb 1/1 Running 0 61s [root@master-node Chapter04]# kubectl get rc -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR kubia 3 3 3 88s kubia luksa/kubia app=kubia [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-8dcg5 1/1 Running 0 101s 10.244.2.43 node-2 <none> <none> kubia-94mq8 1/1 Running 0 101s 10.244.1.8 node-1 <none> <none> kubia-kghvb 1/1 Running 0 101s 10.244.2.44 node-2 <none> <none> [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-8dcg5 1/1 Running 0 118s app=kubia kubia-94mq8 1/1 Running 0 118s app=kubia kubia-kghvb 1/1 Running 0 118s app=kubia [root@master-node Chapter04]#
从上面的输出结果,我们看到名为kubia的ReplicationController的相关信息,期望(DESIRED)3个pod副本,当前是3个,且READY就绪的也是3个。同时看到了它的SELECTOR是app=kubia,接下来看到3个pod的状态是Running,且它们的label也是app=kubia。
2.5 构成ReplicationController的3元素
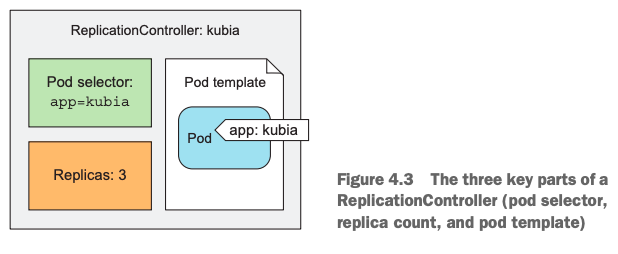
- pod副本数:由spec字段下的replicas字段描述,不指定的话,默认值为1。上述是replicas: 3。限定当前ReplicationController管理的pod的副本数;
- label selector:spec字段下显示指出,用selector字段标识;用于判定哪些pod属于当前ReplicationController管理;
- template:用来指定当前ReplicationController管理的pod的模板;即它管理的pod具有哪些特征,pod的label是什么?pod中的container的相关信息等。
2.6 验证ReplicationController水平扩展pod的场景
接下来,我们通过修改kubia的replics字段的副本数,来让ReplicationController自动帮我们扩缩容pod。这模拟了生产环境中,我们需要动态扩缩容应用的场景,比如发现业务高峰期到来、电商大促、月末结账等,需要扩容;在比如业务高峰期过去,需要缩容应用,以节省软硬件成本等。
我们可以直接修改yaml文件中的replicas数值,然后再执行kubectl apply -f kubia-rc.yaml,也可以直接kubectl edit rc kubia的命令行方式直接修改并保存。
这里,先通过修改kubia-rc.yaml文件,再kubectl apply -f kubia-rc.yaml,将其扩容到5个副本:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat kubia-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 5
selector:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
[root@master-node Chapter04]# kubectl apply -f kubia-rc.yaml
replicationcontroller/kubia configured
[root@master-node Chapter04]# kubectl get rc
NAME DESIRED CURRENT READY AGE
kubia 5 5 5 10h
[root@master-node Chapter04]# kubectl get pods
NAME READY STATUS RESTARTS AGE
kubia-8dcg5 1/1 Running 0 10h
kubia-94mq8 1/1 Running 0 10h
kubia-jsz8w 1/1 Running 0 9s
kubia-kghvb 1/1 Running 0 10h
kubia-s4fjj 1/1 Running 0 9s
[root@master-node Chapter04]# 很快,命令下发给Kubernetes API server之后,我们看到ReplicationController的状态发生变化,同时看到新启动了2个pod。
接下来,我们通过kubectl edit rc kubia的命令行方式,在线修改配置文件,并保存退出。默认使用当前shell的默认编辑器Vi编辑器。这里,我们将其缩容为2个副本。
[root@master-node Chapter04]# kubectl edit rc kubia
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: ReplicationController
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"ReplicationController","metadata":{"annotations":{},"name":"kubia","namespace":"default"},"spec":{"replicas":5,"selector":{"app":"kubia"},"template":{"metadata":{"labels":{"app":"kubia"}},"spec":{"containers":[{"image":"luksa/kubia","name":"kubia","ports":[{"containerPort":8080}]}]}}}}
creationTimestamp: "2022-03-05T15:38:25Z"
generation: 2
labels:
app: kubia
name: kubia
namespace: default
resourceVersion: "6749470"
uid: 5d7a6a22-c88f-4592-86ff-49d3e85172f0
spec:
replicas: 5 #我们将这里的5改成2,保存退出即可。
selector:
app: kubia
....
...
ports:
- containerPort: 8080
protocol: TCP
resources: {}
"/tmp/kubectl-edit-2703824518.yaml" 49L, 1548C written
replicationcontroller/kubia edited
[root@master-node Chapter04]# kubectl get rc
NAME DESIRED CURRENT READY AGE
kubia 2 2 2 10h
[root@master-node Chapter04]# kubectl get pods
NAME READY STATUS RESTARTS AGE
kubia-8dcg5 1/1 Terminating 0 10h
kubia-94mq8 1/1 Running 0 10h
kubia-jsz8w 1/1 Terminating 0 5m27s
kubia-kghvb 1/1 Running 0 10h
kubia-s4fjj 1/1 Terminating 0 5m27s
[root@master-node Chapter04]# 从输出结果上,我们看到3个pod的状态是Terminating,过一会儿,它们就消失了。只剩下2个pod在Running。
补充:水平扩展也有单独的命令:kubectl scale replicationcontroller kubia –replicas=3;如下:
[root@master-node Chapter04]# kubectl scale replicationcontroller kubia --replicas=3 replicationcontroller/kubia scaled [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-gqlfd 0/1 ContainerCreating 0 2s kubia-kghvb 1/1 Running 0 22h kubia-z597v 1/1 Running 0 10h [root@master-node Chapter04]# kubectl scale replicationcontroller kubia --replicas=2 replicationcontroller/kubia scaled [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-gqlfd 1/1 Terminating 0 45s kubia-kghvb 1/1 Running 0 22h kubia-z597v 1/1 Running 0 10h [root@master-node Chapter04]#
2.7 ReplicationController水平扩展pod的底层原理
上面,我们看到了通过ReplicationController来管理pod的便利和优势,可以动态快速扩缩容。那么ReplicationController是怎么做到的呢?
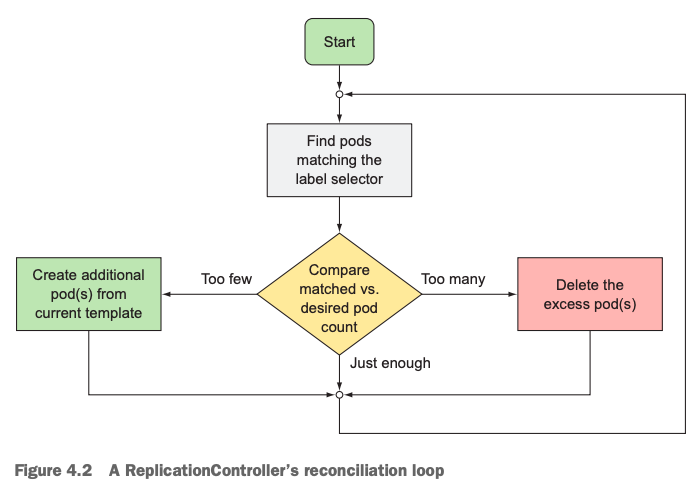
ReplicationController持续的监控运行着的pod的个数是不是和它期望的个数相匹配,如果多了,那么它就删掉多余的,否则,就按照它要求的个数(replicas字段值)补齐差额。类似于”多退少补”的场景,小朋友抓了一把硬币(pods)去杂货铺找老爷爷(ReplicationController)买棒棒糖一样。
A ReplicationController constantly monitors the list of running pods and makes sure the actual number of pods of a “type” always matches the desired number. If too few such pods are running, it creates new replicas from a pod template. If too many such pods are running, it removes the excess replicas.
p123
如下是ReplicationController的协调底层pod的工作原理图:
2.8 ReplicationController自动维护pod的场景验证
前面,我们说手工创建的pod一旦出现问题,或者它所在node出现故障,pod将不会被Kubernetes接管。现在我们通过ReplicationController来创建了2个pod,接下来,我们动手验证一下,手工强制删除1个pod,会有什么结果?
删除前:
[root@master-node Chapter04]# kubectl get rc NAME DESIRED CURRENT READY AGE kubia 2 2 2 12h [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-94mq8 1/1 Running 0 12h kubia-kghvb 1/1 Running 0 12h [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-94mq8 1/1 Running 0 12h 10.244.1.8 node-1 <none> <none> kubia-kghvb 1/1 Running 0 12h 10.244.2.44 node-2 <none> <none> [root@master-node Chapter04]#
删除:kubectl delete pod kubia-94mq8
[root@master-node Chapter04]# kubectl delete pod kubia-94mq8 pod "kubia-94mq8" deleted [root@master-node Chapter04]#
删除过程中:
[root@master-node Chapter04]# kubectl get rc NAME DESIRED CURRENT READY AGE kubia 2 2 2 12h [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-94mq8 1/1 Terminating 0 12h kubia-kghvb 1/1 Running 0 12h kubia-z597v 1/1 Running 0 17s [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-94mq8 1/1 Terminating 0 12h 10.244.1.8 node-1 <none> <none> kubia-kghvb 1/1 Running 0 12h 10.244.2.44 node-2 <none> <none> kubia-z597v 1/1 Running 0 22s 10.244.1.10 node-1 <none> <none> [root@master-node Chapter04]#
删除后:
[root@master-node Chapter04]# kubectl get rc NAME DESIRED CURRENT READY AGE kubia 2 2 2 12h [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-kghvb 1/1 Running 0 12h kubia-z597v 1/1 Running 0 42s [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kubia-kghvb 1/1 Running 0 12h 10.244.2.44 node-2 <none> <none> kubia-z597v 1/1 Running 0 45s 10.244.1.10 node-1 <none> <none> [root@master-node Chapter04]#
由ReplicationController管理的pod,即使我们强制删除1个pod:kubectl delete pod kubia-94mq8 ,然后ReplicationController感知到当前的pod只有1个,不符合预期的2个pod,于是再帮我们启动1个名为kubia-z597v的pod。这,就是我们为什么一直强调说我们不要自己手动去创建和管理pod原因,而应该通过Deployment或者其它控制器去管理和维护pod。
此外,如果我们把其中一个pod(kubia-kghvb)所在的节点node-2直接关掉,或者断掉网络,使其脱离当前整个Kubernetes cluster的话,我们也可以看到ReplicationController会感知到该场景,并且在其它可用节点上重新拉起一个pod来。
2.9 ReplicationController和pod之间的关联关系是什么?
它俩是通过label selector和label产生关联关系的。pod有label,ReplicationController有label selector。label selector才是灵魂,架起二者关联关系的桥梁和纽带。好比如你有上等的勃艮第,我有1个开瓶器,你有口感极佳的啤酒花,我有一个啤酒瓶。还有花生米和故事。
对于ReplicationController而言,我不在意你pod的名字是什么,你运行在哪个node上,这些我统统不关心。我只看你pod的label和我的label selector是不是匹配?匹配的话,你就归我管,否则咱俩没关系。
2.10 手工修改pod的label使其脱离ReplicationController的场景和后果?
前面我们说了,pod上有label,ReplicationController有label selector,然后这二者之间产生了关联关系。那么,如果我们把其中1个pod的label改成其它,使其脱离当前ReplicationController会有什么结果呢?
当然啦, 在说 结果之前,
修改前:
[root@master-node Chapter04]# kubectl get rc NAME DESIRED CURRENT READY AGE kubia 2 2 2 19h [root@master-node Chapter04]# kubectl get rc -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR kubia 2 2 2 19h kubia luksa/kubia app=kubia [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-kghvb 1/1 Running 0 19h app=kubia kubia-z597v 1/1 Running 0 6h47m app=kubia [root@master-node Chapter04]#
修改名为kubia-z597v的pod,使其label为:app=no-kubia
[root@master-node Chapter04]# kubectl label pod kubia-z597v app=no-kubia --overwrite pod/kubia-z597v labeled [root@master-node Chapter04]#
修改之后,ReplicationController和pod的信息如下:
[root@master-node Chapter04]# kubectl label pod kubia-z597v app=no-kubia --overwrite pod/kubia-z597v labeled [root@master-node Chapter04]# kubectl get rc -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR kubia 2 2 1 19h kubia luksa/kubia app=kubia [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-h26kx 1/1 Running 0 11s app=kubia kubia-kghvb 1/1 Running 0 19h app=kubia kubia-z597v 1/1 Running 0 6h49m app=no-kubia [root@master-node Chapter04]#
我们看到,ReplicationController发现期望的pod是2个,当前只有1个,于是立即启动1个新的pod名为kubia-h26kx,使其满足预期目标。同时,我们看到被修改label的pod也正常运行,只是,此时它已经脱离了ReplicationController的管控,如果此时该pod出现异常的话,ReplicationController不会重启它。类似于没有家长看管的野小子一样。
反过来,如果我们把kubia-z597v的label从app=no-kubia再重新修改为app=kubia,又会是什么结果呢?
再次修改:
[root@master-node Chapter04]# kubectl label pod kubia-z597v app=kubia --overwrite pod/kubia-z597v unlabeled [root@master-node Chapter04]#
结果:
[root@master-node Chapter04]# kubectl get rc -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR kubia 2 2 2 19h kubia luksa/kubia app=kubia [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-h26kx 1/1 Terminating 0 7m12s app=kubia kubia-kghvb 1/1 Running 0 19h app=kubia kubia-z597v 1/1 Running 0 6h56m app=kubia [root@master-node Chapter04]#
再一次,我们看到kubia-h26kx重新回到了组织的管辖之中,而ReplicationController会把之前新建的pod kubia-h26kx终止掉,以使得它满足预期的转态,只有2个pod的副本。
2.11手工修改ReplicationController的label selector结果是?
接下来,我们再做另外一个实验,手工把名为kubia的这个ReplicationController的label selector修改我app=kubia-bye,这样,使当前label为app=kubia的2个pod都不受其管控,也就是说,当前没有任何pod满足它的label selector。看看结果会是怎样的?
修改前:
[root@master-node Chapter04]# kubectl get rc -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR kubia 2 2 2 22h kubia luksa/kubia app=kubia [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-kghvb 1/1 Running 0 22h app=kubia kubia-z597v 1/1 Running 0 10h app=kubia [root@master-node Chapter04]#
修改,保存:
[root@master-node Chapter04]# kubectl edit rc
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: ReplicationController
...
spec:
replicas: 2
selector:
app: kubia-bye #我们将ReplicationController的selector改为app=kubia-bye
template:
metadata:
creationTimestamp: null
labels:
app: kubia
spec:然后,看看结果,提示保存失败。
A copy of your changes has been stored to "/tmp/kubectl-edit-2419887689.yaml"
error: Edit cancelled, no valid changes were saved.
[root@master-node Chapter04]# kubectl describe rc kubia
Name: kubia
Namespace: default
Selector: app=kubia
Labels: app=kubia
Annotations: <none>
Replicas: 2 current / 2 desired
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=kubia
Containers:
kubia:
Image: luksa/kubia
Port: 8080/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events: <none>
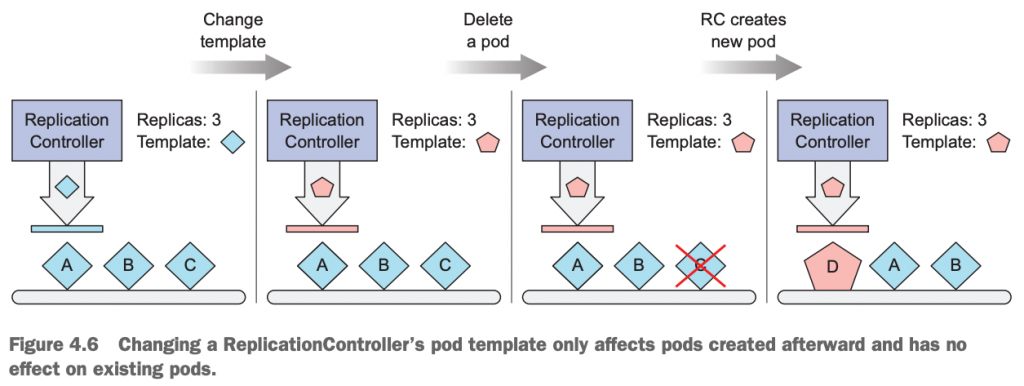
[root@master-node Chapter04]# 从理论上来讲,我们希望的是,当我们修改完ReplicationController的label selector之后,原来由它管理的pod被动脱离它的管控,然后它自己根据新的label selector再去找新的pod。但是,这是不被允许的,在实际工作当中,也没有实际意义。但是,我们可以通过修改ReplicationController里的pod template中的字段。注意,这种修改方式只对新创建的pod生效,对已经存在的pod不会有影响。
2.12如何修改ReplicationController的pod template模板字段及其应用场景
我们可以直接通过kubectl edit rc your_rc_name来对ReplicationController中的pod template字段进行修改,保存之后就自动生效。注意,该修改不对已经存在的pod生效,只对将来新创建的pod生效。
那么这种修改有何应用场景呢?
比如如果我们希望升级我们的pod,就可以通过修改pod template自动,改动其image相关信息,然后手工删除1个pod,ReplicationController会自动根据新的模板,拉起1个pod出来,这样就变向的完成了应用的版本升级。再比如,我们想修改pod的端口号(其实是修改pod中的container的端口号)。如下是一个修改ReplicationController的pod template的流程图:
2.13 只删除ReplicationController不删除它管理的pod
我们可以通过kubectl delete replicationcontroller rc_name;来删除ReplicationController以及由它管理的pod。但是,这里我们想单独删除ReplicationController,保留它管理的pod。接下来,我们会创建1个ReplicaSet,并把这些pod纳入到ReplicaSet的管理范畴。
删除ReplicationController的命令是:kubectl delete replicationcontroller your_replication_controller_name;通过在该命令上添加–cascade=orphan的选项,使得单独删除ReplicationController,而保留其管理的pod正常运行。从命令行上,我们就可以显然知道啥意思了,orphan字面意思是”孤儿”的意思,删除ReplicationController时带上这个选项,不就是说使其管理的pod变成“孤儿”,处于无人看管的状态吗。
删除前:
[root@master-node Chapter04]# kubectl get rc -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR kubia 2 2 2 34h kubia luksa/kubia app=kubia [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-kghvb 1/1 Running 0 34h app=kubia kubia-z597v 1/1 Running 0 22h app=kubia [root@master-node Chapter04]#
删除:
[root@master-node Chapter04]# kubectl delete replicationcontrollers kubia --cascade='false' warning: --cascade=false is deprecated (boolean value) and can be replaced with --cascade=orphan. replicationcontroller "kubia" deleted [root@master-node Chapter04]# kubectl get rc -owide No resources found in default namespace. [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-kghvb 1/1 Running 0 35h app=kubia kubia-z597v 1/1 Running 0 22h app=kubia [root@master-node Chapter04]#
从上,看到,之前版本的命令行选项,是–cascade=’false’,现在已经废弃了,被–cascade=orphan取代了。同时,看到ReplicationController被删除消失了,之前被其管控的pod依然存在。
3 ReplicaSet控制器
3.1 什么是ReplicaSet
最初,ReplicationController是Kubernetes中唯一一个可以创建pod副本和重新调度pod的组件。后来,一个具有类似功能的资源组件被引入了,那就是ReplicaSet。它是ReplicationController的新一代替代品,慢慢的ReplicationController将被废弃了。
3.2 ReplicaSet有什么用
ReplicaSet的目的就是确保在任何时刻都维持一个pod的所有副本数是稳定运行的。用于保证特定数目个相同的pod都是可用状态。
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods.
—-参考Kubernetes官网文档:https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
3.3 ReplicaSet的使用场景
但凡可以使用ReplicationController的场景,完全可以使用ReplicaSet去取代。也就是说,我们在前面一个小节里花了大量时间学习和掌握的ReplicationController的知识技能,现在完全可以平滑过渡到ReplicaSet上了。
当然,Kubernetes官方的建议依然是,我们不要直接去使用ReplicaSet,而应该使用位于其上层的抽象对象Deployment,我们先暂且了解到这儿。后面还会专门再学习和使用Deployment的。官方也说,如果我们确信我们的应用需要客户化的方式去编排管理,或者我们的应用压根儿就不需要更新的话,我们可以考虑使用ReplicaSet。
When to use a ReplicaSet
A ReplicaSet ensures that a specified number of pod replicas are running at any given time. However, a Deployment is a higher-level concept that manages ReplicaSets and provides declarative updates to Pods along with a lot of other useful features. Therefore, we recommend using Deployments instead of directly using ReplicaSets, unless you require custom update orchestration or don’t require updates at all.
This actually means that you may never need to manipulate ReplicaSet objects: use a Deployment instead, and define your application in the spec section.
https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/#when-to-use-a-replicaset
3.4 ReplicaSet和ReplicationController的对比
- 标签选择器上:ReplicaSet有了更为广泛的使用方式,比如对于env=prd和env=test这两种不同label的pod,ReplicaSet可以通过一个“包含key为env的选择器”可以把它们都选中;而ReplicationController却做不到这一点儿,要么选择label是env=prd的pod或者labels是env=test的pod,却不能同时选中这两种label的所有pods;即ReplicationController只能从env=prd和env=test中二选一,而ReplicaSet可以通过env=*,同时选择。
- 资源版本号:ReplicaSet的资源版本是apps/v1;而ReplicationController的版本是v1;
- 支持跟更丰富的label selector上:ReplicaSet支持更为丰富的表达式标签选择器,比如可以使用matchLabels,或者matchExpressions等字段;而ReplicationController只支持selector字段;
ReplicaSets are the successors to ReplicationControllers. The two serve the same purpose, and behave similarly, except that a ReplicationController does not support set-based selector requirements as described in the labels user guide. As such, ReplicaSets are preferred over ReplicationControllers
Kubernetes官网:https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/#replicationcontroller
3.5 如何创建和使用ReplicaSet
先看ReplicaSet的yaml文件:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat kubia-replicaset.yaml
apiVersion: apps/v1 #作者在书中使用旧版本的Kubernetes,这里的版本是apps/v1beta2,现在新版本Kubernetes使用apps/v1作为ReplicaSet资源的版本号。
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
[root@master-node Chapter04]# 看到ReplicaSet的apiVersion不再是v1,而是apps/v1。它的label selector,不再用selector字段,而是matchLables,其含义是要求严格匹配app=kubia的pod的label。其它配置项跟之前的ReplicationController几乎一致,没有任何两样。
使用作者在书中使用的版本号apps/v1beta2,在当前版本(V1.23)的Kubernetes会报错:
[root@master-node Chapter04]# kubectl apply -f kubia-replicaset.yaml error: unable to recognize "kubia-replicaset.yaml": no matches for kind "ReplicaSet" in version "apps/v1beta2" [root@master-node Chapter04]#
我们需要把版本号更改为:apps/v1,然后再来执行创建ReplicaSet:
[root@master-node Chapter04]# kubectl apply -f kubia-replicaset.yaml replicaset.apps/kubia created [root@master-node Chapter04]# kubectl get replicasets.apps NAME DESIRED CURRENT READY AGE kubia 3 3 3 10s [root@master-node Chapter04]# kubectl get replicasets.apps -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR kubia 3 3 3 15s kubia luksa/kubia app=kubia [root@master-node Chapter04]#
创建之后:
[root@master-node Chapter04]# kubectl get replicasets.apps --show-labels NAME DESIRED CURRENT READY AGE LABELS kubia 3 3 3 36s <none> [root@master-node Chapter04]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS kubia-kghvb 1/1 Running 0 41h app=kubia kubia-z597v 1/1 Running 0 29h app=kubia kubia-zqzmh 1/1 Running 0 65s app=kubia [root@master-node Chapter04]#
我们看到kubia这个ReplicaSet的selector是app=kubia,结果就是之前两个无人认领的pod(kubia-kghvb和kubia-z597v)被kubia纳入麾下,同时它还创建了1个新的pod(kubia-zqzmh),从其启动时间可以判断出来。因为kubia这个ReplicaSet的replicas=3。
我们可以通过查看pod信息来验证:
[root@master-node Chapter04]# kubectl describe pod kubia-kghvb Name: kubia-kghvb Namespace: default Priority: 0 Node: node-2/172.16.11.161 Start Time: Sat, 05 Mar 2022 23:38:26 +0800 Labels: app=kubia Annotations: <none> Status: Running IP: 10.244.2.44 IPs: IP: 10.244.2.44 Controlled By: ReplicaSet/kubia #明显说明该pod是被ReplicaSet/kubia管控的 Containers: ....
3.6 删除ReplicaSet
[root@master-node Chapter04]# kubectl delete rs kubia replicaset.apps "kubia" deleted [root@master-node Chapter04]# kubectl get rs No resources found in default namespace. [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE kubia-kghvb 1/1 Terminating 0 2d15h kubia-z597v 1/1 Terminating 0 2d2h kubia-zqzmh 1/1 Terminating 0 21h [root@master-node Chapter04]#
kubectl delete rs kubia 删除ReplicaSet,过一段时间之后,由它所管理的pods将全部删除消失。
我们同样可以像删除ReplicationController那样指定–cascade=orphan选项,只删除ReplicaSet,而保留pods。
3.7 思考题
如果我们事先创建了2个pod,指定其label为tier=frontend,image为xxx.v1。然后创建1个ReplicaSet,它的pod副本数replicas为3,pod selector为tier=frontend,pod template 中指定pod的image为xxx.v2。会有什么结果?
Kubernetes会先帮我们创建2个pods(image为xxx.v1),然后正常启动ReplicaSet,并把之前的2个pod纳入它的管理范畴,然后再通过自己的yaml文件启动1个pod(image为xxx.v2)。
如果上面的操作我们反过来,先创建ReplicaSet,然后手工创建那2个pod,结果又如何?
Kubernetes会把新建的2个pod纳入ReplicaSet的管辖范畴,然后又立即删掉这2个pod。
$ kubectl get rs -owide NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR frontend 3 3 3 21m php-redis gcr.io/google_samples/gb-frontend:v3 tier=frontend $ kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS frontend-7c6gj 1/1 Running 0 21m tier=frontend frontend-dqg2p 1/1 Running 0 21m tier=frontend frontend-flmhw 1/1 Running 0 21m tier=frontend $ kubectl apply -f https://kubernetes.io/examples/pods/pod-rs.yaml pod/pod1 created pod/pod2 created $ kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS frontend-7c6gj 1/1 Running 0 21m tier=frontend frontend-dqg2p 1/1 Running 0 21m tier=frontend frontend-flmhw 1/1 Running 0 21m tier=frontend pod1 0/1 Terminating 0 2s tier=frontend pod2 0/1 Terminating 0 2s tier=frontend $
这两种情形可能都不是我们希望的结果。这两个案例源于Kubernetes官网:https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/#non-template-pod-acquisitions 演示环境通过官网演示环境:https://kubernetes.io/docs/tutorials/hello-minikube/
结论就是,ReplicaSet管理pod,是根据pod 的label selector去找pod的label,做匹配的。而不是根据pod名,也不是根据其它信息。
3.8 如何确定pod是归属那个ReplicaSet管理的
A ReplicaSet is linked to its Pods via the Pods’ metadata.ownerReferences field, which specifies what resource the current object is owned by. All Pods acquired by a ReplicaSet have their owning ReplicaSet’s identifying information within their ownerReferences field. It’s through this link that the ReplicaSet knows of the state of the Pods it is maintaining and plans accordingly.
比如:
[root@master-node Chapter04]# kubectl get pods kubia-cvff2 -oyaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2022-03-08T07:35:57Z"
generateName: kubia-
labels:
app: kubia
name: kubia-cvff2
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: kubia
uid: bcef3fb0-2f50-4f38-bcb3-4a53341fdb32
resourceVersion: "7019484"
uid: bec22d8d-0c40-419a-8bc7-054fdd9465b9
spec:我们看到,kubia-cvff2的metadata.ownerReferences指向了ReplicaSet控制器,其名称为kubia。
4 DaemonSet控制器
4.1 DaemonSet的特征总结和说明
- 见名知意,类似于操作系统上的守护进程一样。它会在Kubernetes cluster上的每个node上运行且运行1个副本的pod。
- 应用场景:收集节点机器上的日志,监控每个节点的资源使用情况。一个特例:Kubernetes cluster上每个node都在运行的kube-Proxy控制器(kubectl get ds -n kube-system;查看DaemonSet;kubectl get pods -n kube-system -owide|grep kube-proxy;查看对应的pods),其实可以认为是1个DaemonSet。
- 它的yaml文件里不需要像ReplicaSet那样定义replicas字段来限定pod的副本数,因为它自身要求每个节点只运行1个pod副本;也可以理解为默认不显示指出的话,默认值是1个pod副本;
- 它的正常运行不需要master node上的Scheduler调度;即使是那些被打上了不可被调度的污点taint的节点,它也可以在上面正常运行pod;
- 如果某个节点宕机,那么该节点上之前运行的DaemonSet管理的pod不会被重新调度到其它node;而且也不应该被重新调度到其它node,因为它的类型是DaemonSet;
- 如果某个节点上部署的Deployment管理的pod因为意外故障了,那么DaemonSet会重新在该节点上重新启动1个该类型的pod;
- 如果集群中新添加节点,那么新节点上将自动运行DaemonSet管理的应用;
DaemonSet和ReplicaSet的对比图:
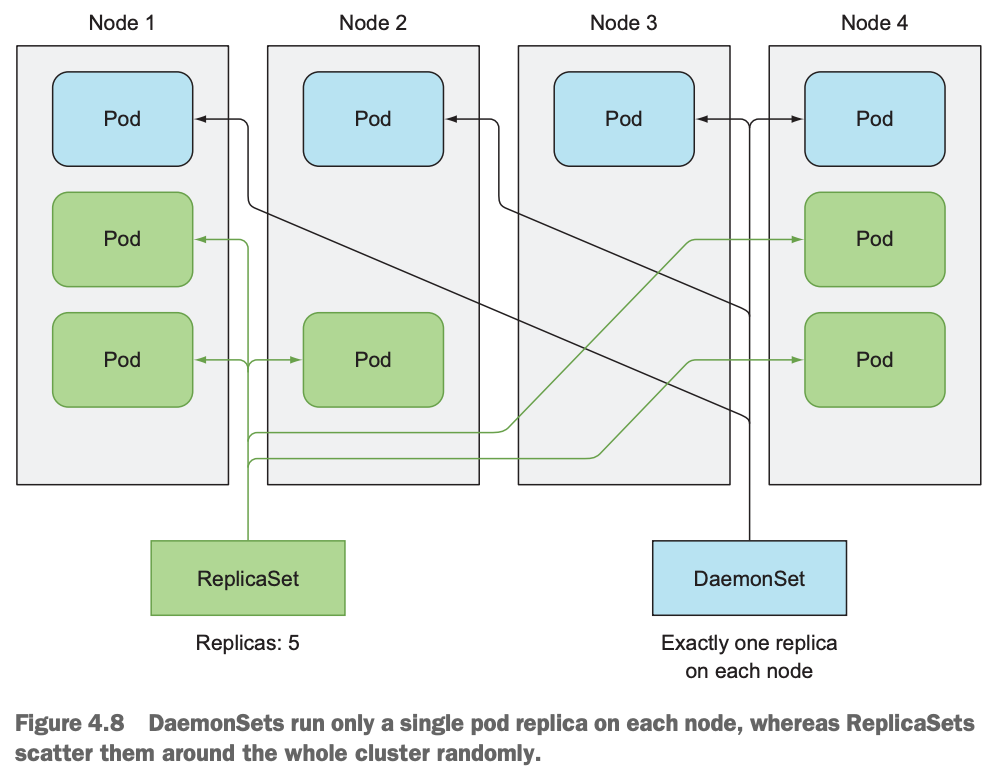
ReplicaSet的5个副本随机分配在4个node上,有的node上有多个,有的node上没有pod;而DaemonSet没有指定副本信息,它会自动在每个node上运行且只运行1个pod,不多不少,不偏不倚。
4.2 DaemonSet示例
示例架构图:
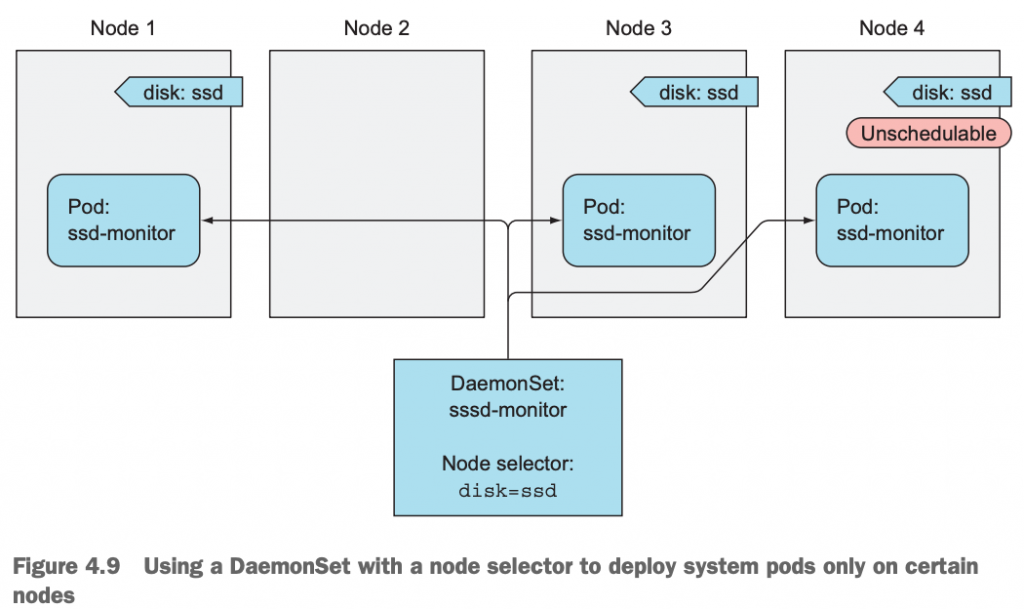
从上,看到,Node2没有disk=ssd的label,所有DaemonSet不会在该节点上部署pod,对于node 4即使被打上污点,不被master节点的Scheduler调度,但是我们的DaemonSet也会在该节点上部署pod,因为它有disk=ssd的label。
示例代码:
[root@master-node Chapter04]# cat ssd-monitor-daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor ##这里只有pod selector,并没有replicas字段
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector: #pod里加了个nodeSelector,只运行在特定的node上
disk: ssd
containers:
- name: main
image: luksa/ssd-monitor
[root@master-node Chapter04]# kubectl apply -f ssd-monitor-daemonset.yaml
daemonset.apps/ssd-monitor created
[root@master-node Chapter04]# kubectl get pods -owide
No resources found in default namespace.
[root@master-node Chapter04]# 执行上述命令之后,发现Kubernetes cluster中并没有任何pod。究其原因是,我们的yaml文件中,pod template里指定了运行在特定node上(node label为disk=ssd)。而当前系统中,并没有满足该label selector的node。
接下来,我们尝试在worker node上打标签:
[root@master-node Chapter04]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS master-node Ready control-plane,master 60d v1.23.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master-node,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers= node-1 Ready <none> 60d v1.22.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,gpu=true,kubernetes.io/arch=amd64,kubernetes.io/hostname=node-1,kubernetes.io/os=linux node-2 Ready <none> 60d v1.22.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node-2,kubernetes.io/os=linux [root@master-node Chapter04]# kubectl label nodes node-1 disk=ssd node/node-1 labeled [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE ssd-monitor-tct7f 1/1 Running 0 6s [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ssd-monitor-tct7f 1/1 Running 0 10s 10.244.1.15 node-1 <none> <none> [root@master-node Chapter04]#
当我们给node-1打上label disk=ssd之后,发现立即有1个pod运行在node-1上了。
反之,当我们给node-1的disk=sdd的标签“撕掉“之后(kubectl label nodes node-1 disk= –overwrite 注意该命令的写法),立即发现该pod被自动杀死了,其实是由它上层的DaemonSet控制器自动帮我们把该pod清理掉。
[root@master-node Chapter04]# kubectl label nodes node-1 disk= --overwrite node/node-1 unlabeled [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ssd-monitor-tct7f 1/1 Terminating 0 2m3s 10.244.1.15 node-1 <none> <none> [root@master-node Chapter04]#
同理,我们给node-2也打上该标签,disk=ssd之后,可以发现又立即启动了新的pod,并运行在node-2之上。
[root@master-node Chapter04]# kubectl label nodes node-2 disk=ssd node/node-2 labeled [root@master-node Chapter04]# kubectl get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE ssd-monitor 2 2 1 2 1 disk=ssd 17h [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE ssd-monitor-hzz62 1/1 Running 0 61s ssd-monitor-qj6qx 1/1 Running 0 17s [root@master-node Chapter04]# kubectl get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE ssd-monitor 2 2 2 2 2 disk=ssd 17h [root@master-node Chapter04]#
4.3 删除DaemonSet
默认情况下,我们删除DaemonSet 控制器资源时,会把它管理的pod一并删除。这里,我们再次使用–cascade=orphan命令行选项,以保留其管理的pods。
[root@master-node Chapter04]# kubectl delete ds ssd-monitor --cascade=orphan daemonset.apps "ssd-monitor" deleted [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE ssd-monitor-hzz62 1/1 Running 0 5m51s ssd-monitor-qj6qx 1/1 Running 0 5m7s [root@master-node Chapter04]#
删除之后,pods被保留了下来,我们查看其中1个pod的metadata.ownerReferences信息:
[root@master-node ~]# kubectl get pod ssd-monitor-hzz62 -oyaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2022-03-09T03:29:25Z"
generateName: ssd-monitor-
labels:
app: ssd-monitor
controller-revision-hash: 5d8c766554
pod-template-generation: "1"
name: ssd-monitor-hzz62
namespace: default
resourceVersion: "7120942"
uid: 40107541-65e0-41bb-8bbd-4f9595652335
spec:
affinity:
...没有任何相关的metadata.ownerReferences字段的信息。接下来,我们再次反向操作,重新创建该DaemonSet,看看结果如何?
[root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE ssd-monitor-hzz62 1/1 Running 0 7m48s ssd-monitor-qj6qx 1/1 Running 0 7m4s [root@master-node Chapter04]# kubectl apply -f ssd-monitor-daemonset.yaml daemonset.apps/ssd-monitor created [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE ssd-monitor-hzz62 1/1 Running 0 7m48s ssd-monitor-qj6qx 1/1 Running 0 7m4s [root@master-node Chapter04]#
发现,Kubernetes并没有帮我们重新创建pod,而是把系统中已有的那2个满足条件(label为app=ssd-monitor)的pod,重新纳入它的管理范畴。并且,再次查看pod的metadata.ownerReferences字段的信息,也可以印证该论断:
[root@master-node Chapter04]# kubectl get pods ssd-monitor-hzz62 -oyaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2022-03-09T03:29:25Z"
generateName: ssd-monitor-
labels:
app: ssd-monitor
controller-revision-hash: 5d8c766554
pod-template-generation: "1"
name: ssd-monitor-hzz62
namespace: default
ownerReferences: #这次,可以看到该字段信息
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: DaemonSet
name: ssd-monitor
uid: 3c38b69c-be95-4f5d-ab8e-b3badd36c426
resourceVersion: "7121112"
uid: 40107541-65e0-41bb-8bbd-4f9595652335
spec:
affinity:5 Job资源控制器
5.1 什么是Job资源
所谓的Job,就是用来控制执行某些特定Pod的资源对象。如果它管控的pod执行成功,就到此为止,pod停止,不再重新启动,也不再继续执行。如果pod由于某些原因失败,或者执行的过程中失败,那么可以配置它管理的pod的重启策略为重启,或者永不重启。
5.2 我们为什么需要Job
比如,我们需要执行某个特定性的一次性任务的场景。那么我们为什么不直接创建1个普通的pod来执行呢?因为,普通pod如果在执行过程中失败了,或者该pod在执行过程中,其所在node失败了,该pod会被重新调度并再次执行。所以,我们搞个Job资源对象,来调度这个pod,就满足我们的需求了。
5.3 Job的特征是什么
它是个一锤子买卖的资源对象,它管控的pod一旦执行成功就结束并退出。不像ReplicaSet,ReplicationController,DaemonSet资源对象那样,控制的pod会持续运行下去。
当然,Job控制的pod如果在执行过程中,pod自身出现故障,或者pod所在node出现故障,那么它也会被Scheduler重新调度到其它node上继续执行,直到执行成功退出。这一点儿跟ReplicaSet,ReplicationController保持一致,而不同于DaemonSet(Pod 所在node出现故障,该pod不会被调度到其它节点)。
Job的yaml文件里,pod template里spec.restartPolicy字段值不能是默认的Always值,只能是OnFailure或者是Never。
5.4 Job有哪些类型
可以配置为串行Job,也可以配置为并行Job。
5.5 普通pod,ReplicaSet和Job对比
如下图,假定普通Pod A,由ReplicaSet管控的Pod B和Job管控的Pod C都在node1上。如果node1出现故障,那么Pod A随之消失,不再被重新调度;Pod B被重新调度,并且持续运行下去;Pod C被重新调度,一旦其执行成功,则退出,不再继续运行。
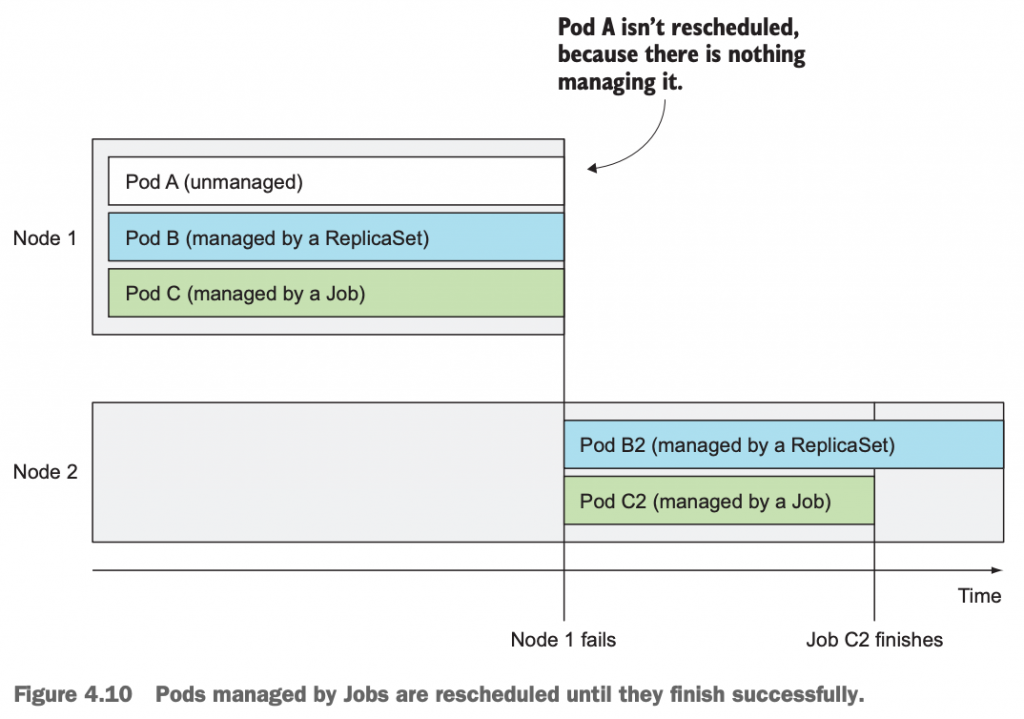
5.6 如何创建和使用job
代码说明:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# ll
总用量 44
drwxr-xr-x 2 root root 24 1月 21 17:34 batch-job
-rw-r--r-- 1 root root 239 1月 21 17:34 batch-job.yaml
-rw-r--r-- 1 root root 371 1月 21 17:34 cronjob.yaml
-rw-r--r-- 1 root root 227 1月 21 17:34 kubia-liveness-probe-initial-delay.yaml
-rw-r--r-- 1 root root 197 1月 21 17:34 kubia-liveness-probe.yaml
-rw-r--r-- 1 root root 293 3月 6 10:23 kubia-rc.yaml
-rw-r--r-- 1 root root 320 3月 8 17:44 kubia-replicaset-matchexpressions.yaml
-rw-r--r-- 1 root root 261 3月 7 17:33 kubia-replicaset.yaml
drwxr-xr-x 2 root root 38 1月 21 17:34 kubia-unhealthy
-rw-r--r-- 1 root root 273 1月 21 17:34 multi-completion-batch-job.yaml
-rw-r--r-- 1 root root 290 1月 21 17:34 multi-completion-parallel-batch-job.yaml
drwxr-xr-x 2 root root 24 1月 21 17:34 ssd-monitor
-rw-r--r-- 1 root root 308 3月 8 17:47 ssd-monitor-daemonset.yaml
-rw-r--r-- 1 root root 280 1月 21 17:34 time-limited-batch-job.yaml
[root@master-node Chapter04]# cat batch-job/Dockerfile
FROM busybox
ENTRYPOINT echo "$(date) Batch job starting"; sleep 120; echo "$(date) Finished succesfully"
[root@master-node Chapter04]# cat batch-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure #注意这里的值不能是默认的default
containers:
- name: main
image: luksa/batch-job
[root@master-node Chapter04]#通过batch-job/Dockerfile build了一个image,luksa/batch-job,它的作用是启动一个容器,打印当前时间,输出一段话,睡眠120秒,打印当前时间,输出执行成功。退出容器。
我们来执行该job:
#执行前 [root@master-node Chapter04]# kubectl get jobs No resources found in default namespace. [root@master-node Chapter04]# kubectl get pods No resources found in default namespace. [root@master-node Chapter04]# #开始执行: [root@master-node Chapter04]# kubectl apply -f batch-job.yaml job.batch/batch-job created [root@master-node Chapter04]# #过几秒之后 [root@master-node Chapter04]# kubectl get jobs NAME COMPLETIONS DURATION AGE batch-job 0/1 9s 10s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE batch-job-znwq5 1/1 Running 0 14s [root@master-node Chapter04]#
查看pod日志,以及继续观察:
[root@master-node Chapter04]# kubectl logs -f batch-job-znwq5 Wed Mar 9 09:26:05 UTC 2022 Batch job starting Wed Mar 9 09:28:05 UTC 2022 Finished succesfully [root@master-node Chapter04]# kubectl get jobs NAME COMPLETIONS DURATION AGE batch-job 1/1 2m12s 2m24s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE batch-job-znwq5 0/1 Completed 0 2m29s [root@master-node Chapter04]#
在预期的时间内,pod执行成功,并退出。pod的状态变为Completed,job的COMPLETIONS字段值是预期的1。
5.7 演示Job管理的pod在执行过程中被杀死的场景
先启动job:
[root@master-node Chapter04]# kubectl apply -f batch-job.yaml job.batch/batch-job created [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE batch-job-zqwdk 0/1 ContainerCreating 0 5s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE batch-job-zqwdk 1/1 Running 0 7s [root@master-node Chapter04]# kubectl logs batch-job-zqwdk Wed Mar 9 09:33:27 UTC 2022 Batch job starting [root@master-node Chapter04]#
手工杀死pod:batch-job-zqwdk
[root@master-node Chapter04]# kubectl delete pod batch-job-zqwdk pod "batch-job-zqwdk" deleted [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE batch-job-bmjgr 1/1 Running 0 28s batch-job-zqwdk 1/1 Terminating 0 57s [root@master-node Chapter04]# kubectl logs batch-job-bmjgr Wed Mar 9 09:33:56 UTC 2022 Batch job starting Wed Mar 9 09:35:56 UTC 2022 Finished succesfully [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE batch-job-bmjgr 0/1 Completed 0 4m56s [root@master-node Chapter04]#
Job如同ReplicaSet或者ReplicationController那样,自动重新帮我们启动了1个新的pod,batch-job-bmjgr,并且直到该pod执行成功退出。
5.8 修改Job中pod的restartPolicy=Always
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat batch-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: Always #我们故意修改其为默认的Always,看看后果如何
containers:
- name: main
image: luksa/batch-job
[root@master-node Chapter04]# kubectl apply -f batch-job.yaml
The Job "batch-job" is invalid: spec.template.spec.restartPolicy: Required value: valid values: "OnFailure", "Never"
[root@master-node Chapter04]#5.9串行job示例
如果我们需要某个特定任务执行多次,我们可以通过设置Job的完成次数字段来实现。
代码:
[root@master-node Chapter04]# cat multi-completion-batch-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
[root@master-node Chapter04]# 创建多个串行job:
[root@master-node Chapter04]# kubectl apply -f multi-completion-batch-job.yaml job.batch/multi-completion-batch-job created [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE multi-completion-batch-job-8rgqq 0/1 ContainerCreating 0 4s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE multi-completion-batch-job-8rgqq 1/1 Running 0 6s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE multi-completion-batch-job-8rgqq 0/1 Completed 0 3m24s multi-completion-batch-job-qzvmh 1/1 Running 0 79s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE multi-completion-batch-job-8rgqq 0/1 Completed 0 14h multi-completion-batch-job-qzvmh 0/1 Completed 0 14h multi-completion-batch-job-tfwdm 0/1 Completed 0 14h multi-completion-batch-job-xckvl 0/1 Completed 0 14h multi-completion-batch-job-zzxls 0/1 Completed 0 14h [root@master-node Chapter04]#
随着时间推移,Job管理的pod1个接着1个的创建起来并运行结束,直至yaml文件里指定的completions: 5全部执行结束。
5.10并行job示例
代码:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat multi-completion-parallel-batch-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5
parallelism: 2
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
[root@master-node Chapter04]# 创建并行的job:
[root@master-node Chapter04]# kubectl delete jobs.batch multi-completion-batch-job job.batch "multi-completion-batch-job" deleted [root@master-node Chapter04]# kubectl apply -f multi-completion-parallel-batch-job.yaml job.batch/multi-completion-batch-job created [root@master-node Chapter04]# kubectl get jobs NAME COMPLETIONS DURATION AGE multi-completion-batch-job 0/5 8s 8s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE multi-completion-batch-job-26czc 1/1 Running 0 13s multi-completion-batch-job-j4jln 1/1 Running 0 13s [root@master-node Chapter04]#
可以看到根据yaml配置文件,multi-completion-batch-job 同时启动了2个pod并行运行。过一段儿时间(container中指定的2分钟),现有的2个pod进入completed状态,同时再启动2个新的pod运行:
[root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE multi-completion-batch-job-26czc 0/1 Completed 0 2m30s multi-completion-batch-job-7mchk 1/1 Running 0 24s multi-completion-batch-job-j4jln 0/1 Completed 0 2m30s multi-completion-batch-job-tnqvb 1/1 Running 0 22s [root@master-node Chapter04]#
直到最后,所有的5个pod都执行完成,结束:
[root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE multi-completion-batch-job-26czc 0/1 Completed 0 4m22s multi-completion-batch-job-7mchk 0/1 Completed 0 2m16s multi-completion-batch-job-j4jln 0/1 Completed 0 4m22s multi-completion-batch-job-k27nv 1/1 Running 0 13s multi-completion-batch-job-tnqvb 0/1 Completed 0 2m14s [root@master-node Chapter04]# kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES multi-completion-batch-job-26czc 0/1 Completed 0 6m15s 10.244.2.70 node-2 <none> <none> multi-completion-batch-job-7mchk 0/1 Completed 0 4m9s 10.244.2.72 node-2 <none> <none> multi-completion-batch-job-j4jln 0/1 Completed 0 6m15s 10.244.2.71 node-2 <none> <none> multi-completion-batch-job-k27nv 0/1 Completed 0 2m6s 10.244.2.74 node-2 <none> <none> multi-completion-batch-job-tnqvb 0/1 Completed 0 4m7s 10.244.2.73 node-2 <none> <none> [root@master-node Chapter04]# kubectl get jobs NAME COMPLETIONS DURATION AGE multi-completion-batch-job 5/5 6m14s 6m22s [root@master-node Chapter04]#
5.11 设置Job执行时长上限
通过Job管理的pod到底需要执行多少时长,是不是可以无限时长,这是个需要考虑的问题,毕竟会消耗系统资源。于是,人们引入了1个activeDeadlineSeconds的字段,用于控制Job管控的pod最多能执行多少时间,到了这个时间限制,Job会终止其管控的pod,无论它是否执行完成,也不管它管控了多少个pods。
代码:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat time-limited-batch-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: time-limited-batch-job
spec:
activeDeadlineSeconds: 30
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
[root@master-node Chapter04]# 创建该Job:
[root@master-node Chapter04]# kubectl get jobs NAME COMPLETIONS DURATION AGE time-limited-batch-job 0/1 5s 5s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE time-limited-batch-job-xvbxt 1/1 Running 0 8s [root@master-node Chapter04]#
超过30秒之后,该Job管控的pod被Job终止:
[root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE time-limited-batch-job-xvbxt 1/1 Terminating 0 52s [root@master-node Chapter04]#
5.12 删除job
[root@master-node Chapter04]# kubectl delete jobs batch-job job.batch "batch-job" deleted [root@master-node Chapter04]# kubectl get pods No resources found in default namespace. [root@master-node Chapter04]#
删除job之后,由它管理的pod也一并被删除。
5.13 设置Job执行成功之后自动删除示例
通过设置spec.ttlSecondsAfterFinished字段来控制Job在执行成功多长时间,它自动删除。如果该字段值设置为0,则Job执行完成之后,立即自动删除;如果该字段值未设置或留空,则该Job在执行成功之后,不会自动删除。
代码:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat pi-with-ttl.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
[root@master-node Chapter04]# 测试验证:
[root@master-node Chapter04]# kubectl apply -f pi-with-ttl.yaml job.batch/pi-with-ttl created [root@master-node Chapter04]# kubectl get jobs NAME COMPLETIONS DURATION AGE pi-with-ttl 0/1 4s 4s [root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE pi-with-ttl-rppbc 0/1 ContainerCreating 0 22s [root@master-node Chapter04]#
过段儿时间之后:
[root@master-node Chapter04]# kubectl get pods NAME READY STATUS RESTARTS AGE pi-with-ttl-rppbc 0/1 Completed 0 3m37s [root@master-node Chapter04]# .... [root@master-node Chapter04]# kubectl get jobs No resources found in default namespace. [root@master-node Chapter04]# kubectl get pods No resources found in default namespace. [root@master-node Chapter04]#
5.14 为什么Job执行成功之后不会自动删除
从官方文档上的解释:https://kubernetes.io/docs/concepts/workloads/controllers/job/#job-termination-and-cleanup
When a Job completes, no more Pods are created, but the Pods are usually not deleted either. Keeping them around allows you to still view the logs of completed pods to check for errors, warnings, or other diagnostic output. The job object also remains after it is completed so that you can view its status. It is up to the user to delete old jobs after noting their status. Delete the job with
kubectl(e.g.kubectl delete jobs/piorkubectl delete -f ./job.yaml). When you delete the job usingkubectl, all the pods it created are deleted too.
用于查看日志,并没有其它作用。
就是可以控制执行特定的任务(Pod)的资源,执行完成之后,就停止了,不再重复执行。如果执行失败了,可以配置成重启,或者即使失败也永不重启。
6 CronJob资源控制器
6.1 什么是CronJob
见名知意,跟Unix、Linux系统上的定时任务异曲同工。用来控制Job在未来的特定时间点儿上周期性的执行,比如数据库的定时备份,可以设置为每天凌晨1点执行。
6.2 CronJob应用场景
常用于定时备份,定时生产报表等场景
6.2 如何创建CronJob
创建1个每隔15分钟执行的CronJob:
[root@master-node Chapter04]# pwd
/root/kubernetes-in-action/Chapter04
[root@master-node Chapter04]# cat cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
schedule: "0,15,30,45 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
[root@master-node Chapter04]# kubectl apply -f cronjob.yaml
Warning: batch/v1beta1 CronJob is deprecated in v1.21+, unavailable in v1.25+; use batch/v1 CronJob
cronjob.batch/batch-job-every-fifteen-minutes created
[root@master-node Chapter04]# kubectl get cronjobs.batch
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
batch-job-every-fifteen-minutes 0,15,30,45 * * * * False 0 <none> 32s
[root@master-node Chapter04]# kubectl get pods
No resources found in default namespace.
[root@master-node Chapter04]# 注意:创建命令中的警告信息。Warning: batch/v1beta1 CronJob is deprecated in v1.21+, unavailable in v1.25+; use batch/v1 CronJob
6.3 CronJob语法格式
其实跟Unix、Linux上创建定时任务保持一致的格式:
# ┌───────────── minute (0 - 59) # │ ┌───────────── hour (0 - 23) # │ │ ┌───────────── day of the month (1 - 31) # │ │ │ ┌───────────── month (1 - 12) # │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday; # │ │ │ │ │ 7 is also Sunday on some systems) # │ │ │ │ │ # │ │ │ │ │ # * * * * *
7 ReplicationController、ReplicaSet、DaemonSet、Job、CronJob对比
| 是否支持replicas字段 | 是否支持多个pods/node | PodFailureRestart | Node故障,Pod重新调度 | 是否受Master node Scheduler调度 | 任务执行完是否退出 | 是否支持串行 | 是否支持TTL-after-finished controller | |
|---|---|---|---|---|---|---|---|---|
| ReplicationController | 是 | 是 | Always | 是 | 是 | 否 | 否 | 否 |
| ReplicaSet | 是 | 是 | Always | 是 | 是 | 否 | 否 | 否 |
| DaemonSet | 否 | 否 | Always | 否 | 否 | 否 | 否 | 否 |
| Job | 是 | 是 | OnFailure/Never | 是 | 是 | 是 | 是 | 是 |
| CronJob | 是 | 是 | OnFailure/Never | 是 | 是 | 是,会再次调度 | 否 | 否 |
TTL(time to live)-after-finished controller是V1.23才支持的新功能.
8 小结
本章中,我们学习了:
如何通过pod的liveness来保证Pod的健康运行;
重点学习了ReplicationController的特征、如何使用、它的作用以及为什么我们需要它;
重点厘清了ReplicationController和Pod之间的关联关系;
学习了ReplicaSet控制器的特征和使用方式;
学习了DaemonSet控制器的特征和使用方式;
学习了Job控制器的特征和使用方式;
学习了CronJob控制器的特征和使用方式;
9 本章思维导图
下载地址:
您可能也喜欢
Kubernetes In Action读书笔记001–概要和说明
如何查看和分析Kubernetes中pod的phase、conditions?它们有什么作用?